Extending the Context of Pretrained LLMs by Dropping their Positional Embeddings
Introduction
Many valuable real-world tasks are long: reviewing a change that touches many files, continuing a month-old chat, or answering questions about a 200-page contract or an hours-long transcript. In these settings, the useful details often lie far into the provided context, and the model must keep track of names, variables, assumptions, instructions, or feedback across long stretches of text. Today’s strongest models do offer large context windows, but their accuracy and recall capabilities considerably suffer once we go past typical sequence lengths seen in training.
“So, why don't we just train on longer sequences?”
Unfortunately, training language models on long sequences is not easy. Part of the difficulty lies in the data: truly long, clean, and relevant contexts are rare and expensive to curate. The other part is compute: attention compares every token to every other token, which means training costs grow quadratically with sequence length -- making long-context training brutally expensive.
Therefore, what we actually want is length generalization: models that were trained on, say, 4k tokens should still reason over 16K or 32K at test time without retraining. Today's transformer LMs often don't. Push them past their training context, and they don't merely get a bit worse; they break: when evaluated out-of-the-box on longer sequences, they fail to produce coherent completions, and even with different scaling tricks
Why does this happen? Transformers need a way to know where tokens are. Raw attention is permutation-invariant (treating its input like a bag of words: “man eats fish” and “fish eats man” look the same if you ignore order), so we need to inject positional information directly into the representations. The standard choice is positional embeddings (PEs), and the dominant one in modern LMs is RoPE (rotary positional embeddings). RoPE is fantastic for training—it bakes in a strong, learnable sense of order. But when we stretch sequences beyond what the model saw during training, RoPE becomes the main culprit: those position-dependent rotations drift out of distribution, and the very mechanism that made learning fast ends up warping long-range attention.
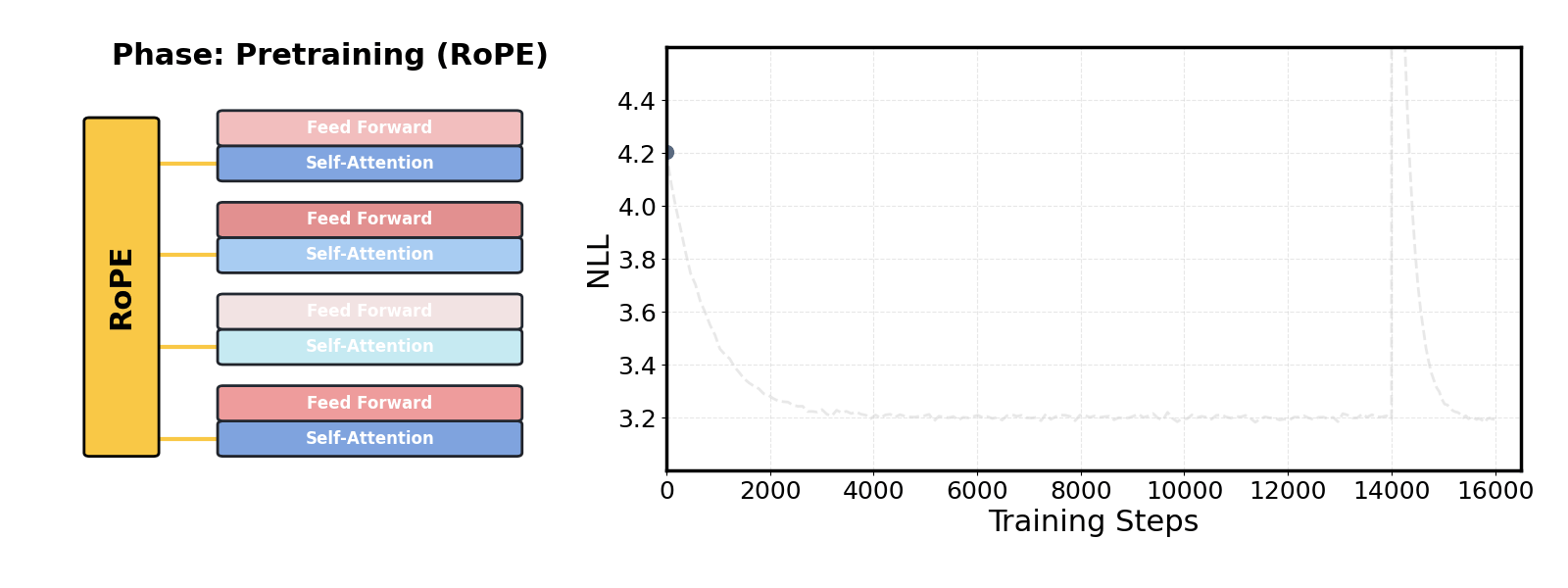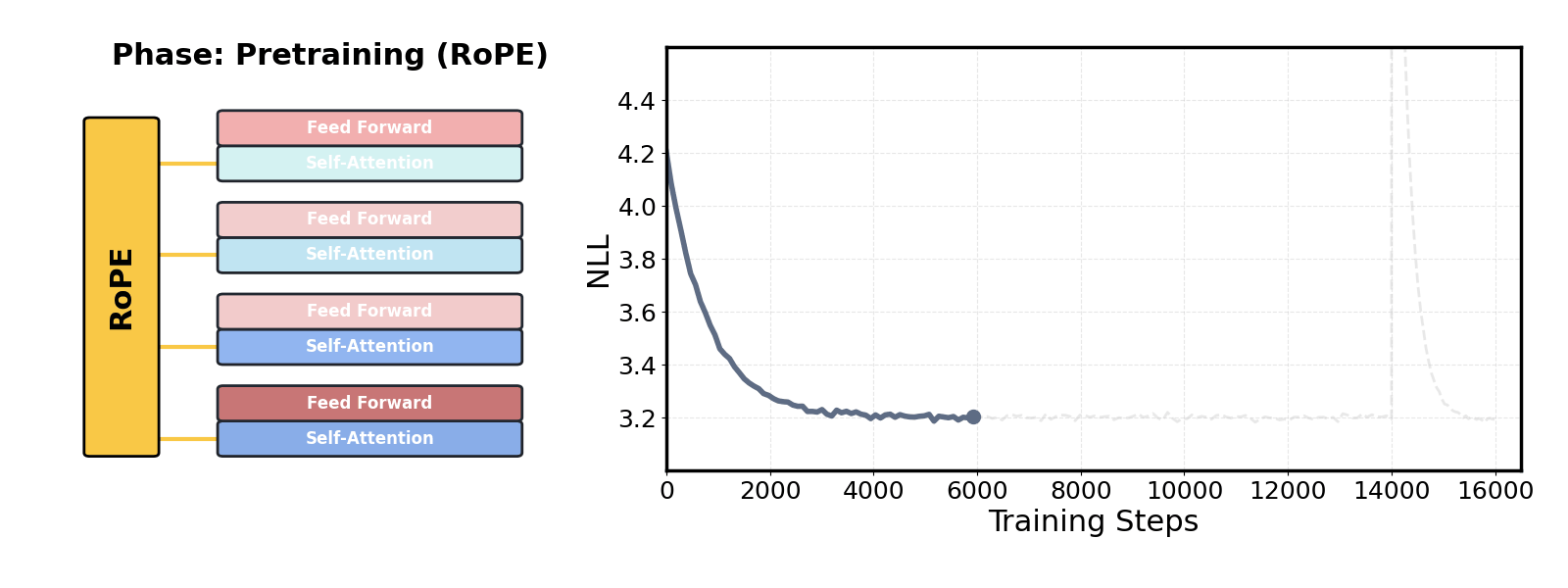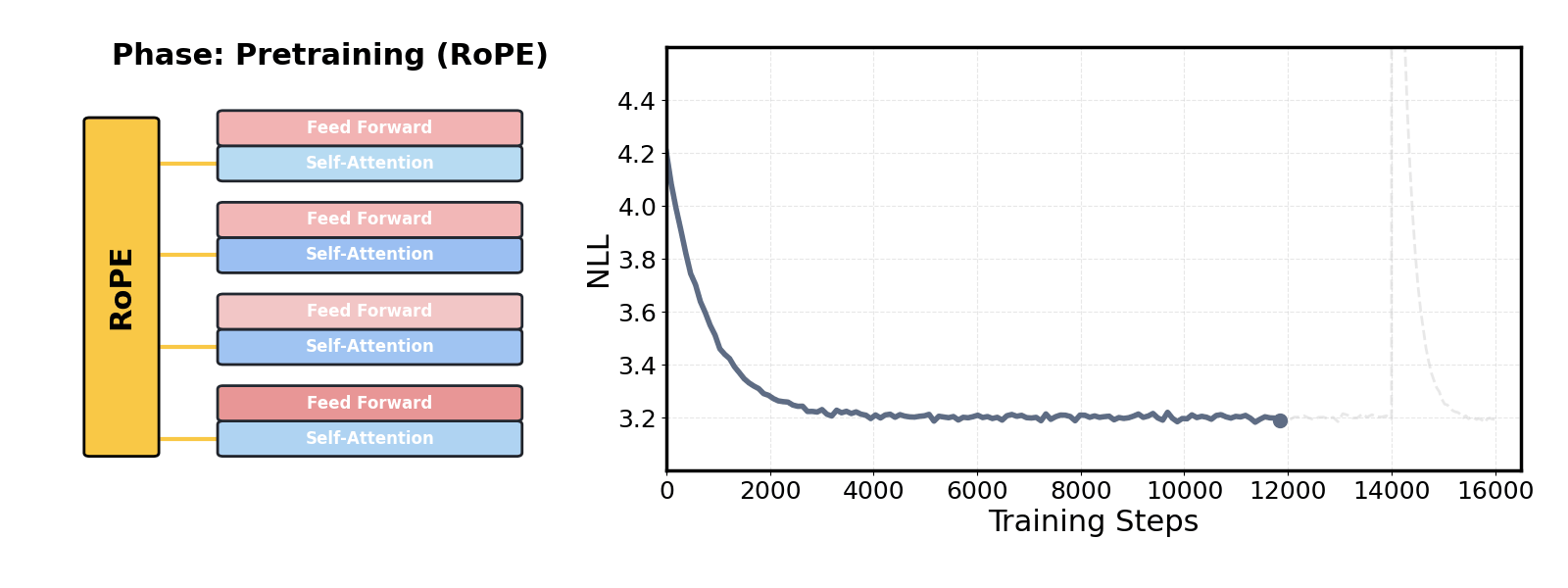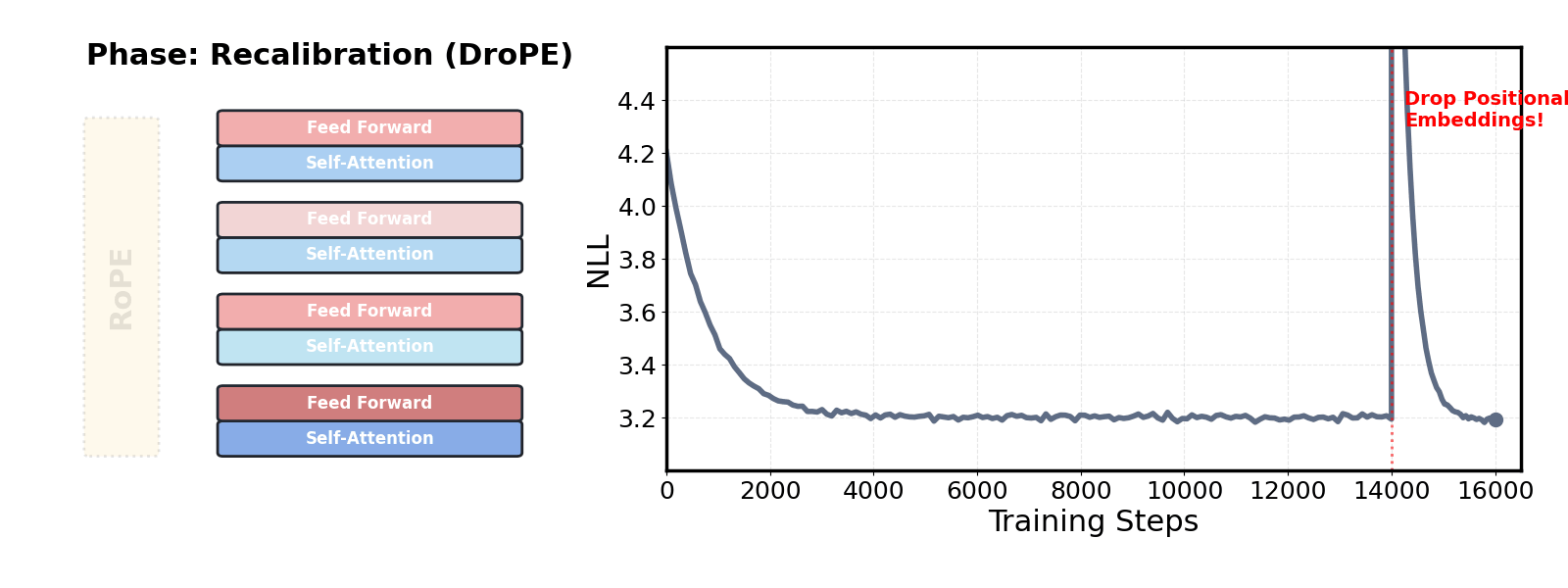
This post digs into that tension, why RoPE helps in-distribution yet undermines extrapolation, and shows a simple path to keep the training benefits without paying the long-context extrapolation price. We introduce DroPE—a simple method for extending a pretrained language model's usable context without long-context fine-tuning:
Just drop the model's positional embeddings after pretraining and run a short recalibration.
The result is a seamless zero-shot context extension that preserves in-context performance and far outperforms RoPE scaling methods and specialized long-context architectures on downstream tasks. We extensively show our method can be easily integrated across small to large parameter and data scales, with results on models with up to 7B parameters and trillions of pretraining tokens.
Why do we need PEs in the first place?
The defining feature of transformers is abandoning architectural inductive biases such as convolutions and recurrences in favor of the highly general self-attention layer. The attention mechanism does not directly encode relative distances between queries and keys. Therefore, raw attention is invariant to prefix permutations: for any permutation , if , then
Therefore, for sequence modeling tasks such as language modeling, we need to directly inject positional information about the tokens through positional embeddings (PE) and causal masking
1
. While the original Attention Is All You Need paper
the token position), injected once for the input tokens, more recently, the community has settled on using Rotary Positional Embeddings, which encodes relative token positions by rotating key and query vectors on every attention head.
Transformers train faster with PEs
While several works have demonstrated the viability of language modeling without positional embeddings (using only the causal masking for positional information), transformers without PE, commonly referred to as NoPE transformers, consistently underperform their PE counterparts. Put differently, under a fixed data and compute budget, a RoPE transformer LM will achieve better results than a NoPE transformer LM.
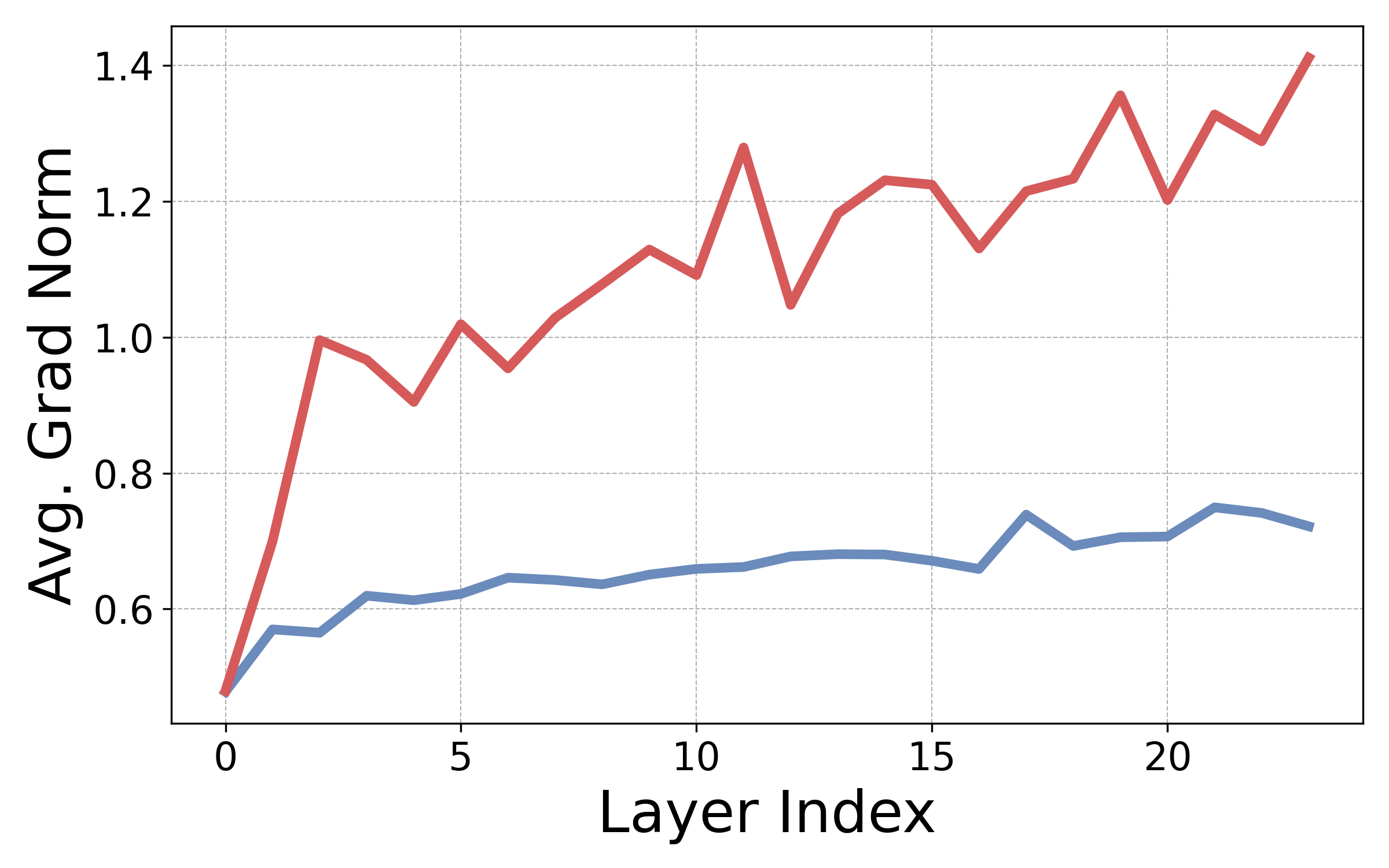
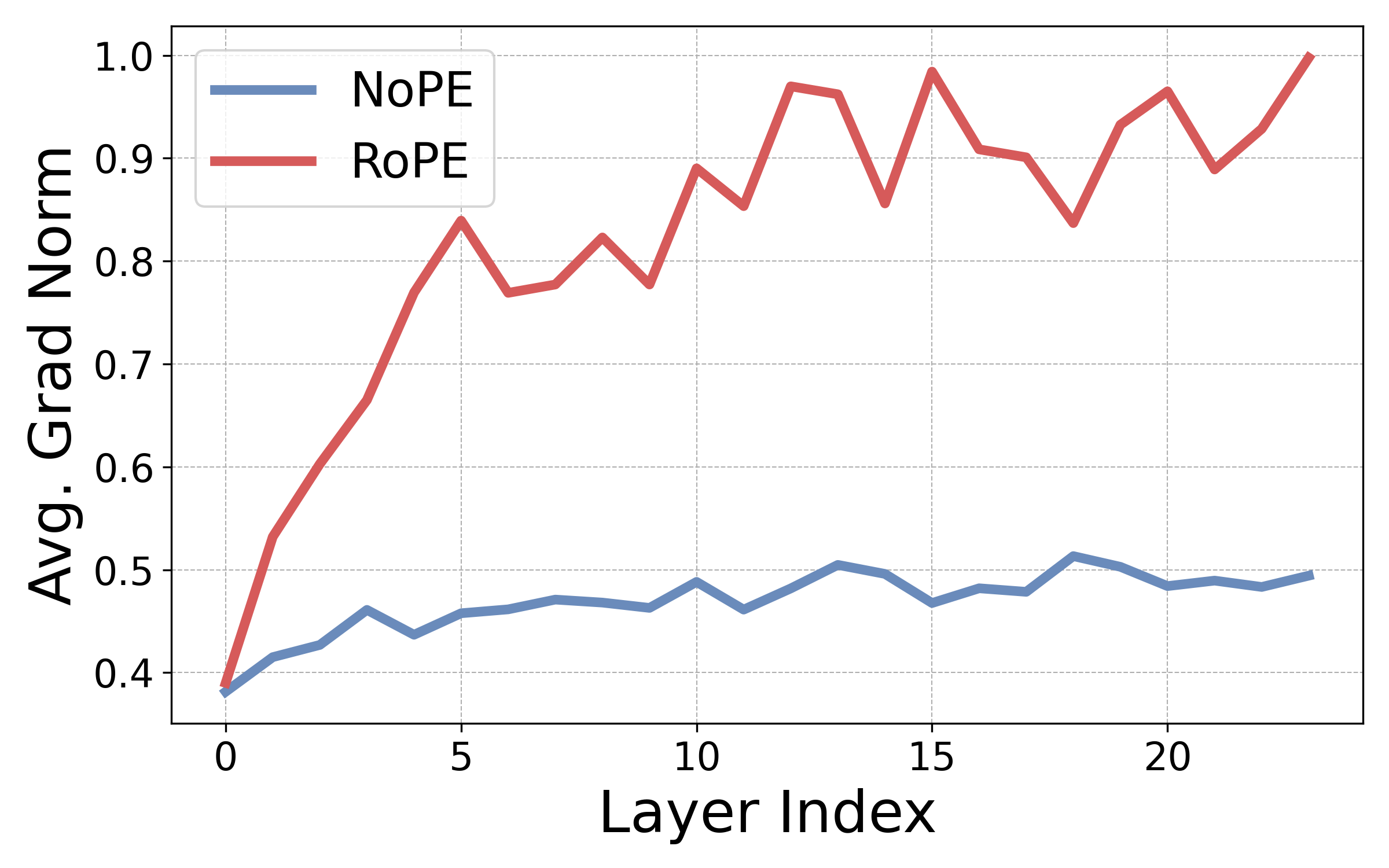
Attention non-uniformity develops faster with RoPE. In essence, our analysis shows that RoPE plays a crucial role in breaking “attention uniformity” in transformer LMs, providing models with an important inductive bias that allows the model to efficiently learn important positional-aware features in its parameters. First, we define a non-uniformity measure for attention heads that captures the alignment of the head with a predefined positional pattern
Here, encodes the positional pattern we are interested in. We then empirically examine ’s gradients at initialization for transformers with and without PEs. High gradient norm means that positional bias can develop fast, right off the bat, while low gradient norm means that, regardless of data, bias takes time to develop, and the heads remain uniform for a long time. As shown in the Figure below, across all layers, gradient norms are higher for RoPE transformers, meaning that attention heads can become diagonal or off-diagonal much faster. Since we know these types of heads are critical for language modeling, this explains the pretraining gap.
Theory corner
In the full paper, we theoretically prove that the figure above, in fact, represents the general case and that gradient norms are always low for NoPE transformers. We show that in NoPE transformers, the gradients of
Why is long-context hard?
Even as we scale hardware and optimize kernels, self-attention remains a quadratic bottleneck: every token compares to every other token. Training at very long sequence lengths is therefore not just slower, it's disproportionately memory- and compute-hungry. As a consequence of these prohibitive costs coupled with the scarcity of high-quality long context data, most models are pretrained at limited context sizes, with an expectation that they'll still behave appropriately when we stretch them at test time. This "zero-shot context extension" has become a central challenge in developing frontier models.
While long-context performance is impacted by many factors
Positional Embeddings pose a challenge
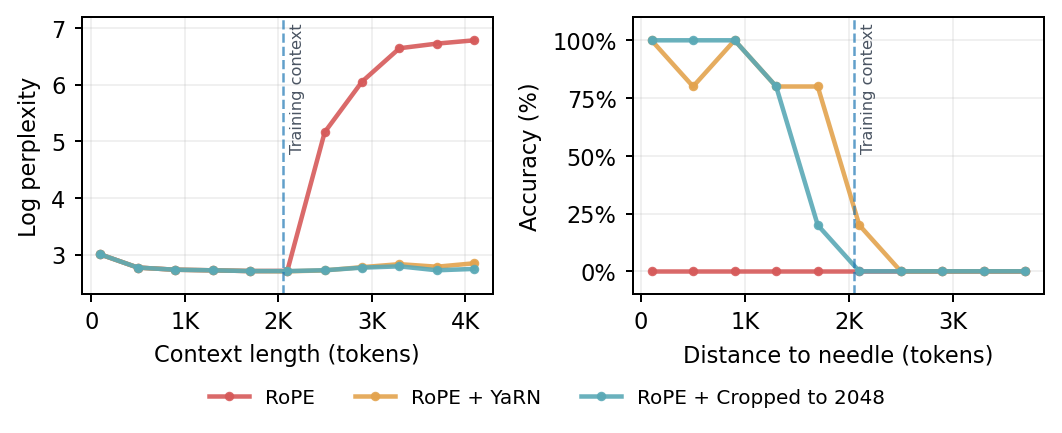
RoPE (and any PE scheme) has a failure mode: when test sequences are longer than what the model saw during training, the induced rotations (phases) move out of distribution. This means attention heads see attention scores never seen in training, and performance drops. Popular “RoPE-scaling” tricks (PI, NTK-aware scaling, YaRN) try to fix this by compressing low frequencies to keep phases in range. That preserves perplexity but quietly shifts semantic heads—the ones that match content across large distances—so the model behaves as if the context were effectively cropped to the original length. In practice, you get near-constant perplexity with poor long-range retrieval—exactly what long-context tasks need most.
why this is inevitable
In standard RoPE, several low frequencies never complete a full cycle over the training window. Extending the context forces any post-hoc scaling to shrink those frequencies by roughly the extension factor (
Embeddings as a train-time scaffold
Taken together, the observations from the previous section imply that PEs are a key component for effective LM training, but are also a fundamental barrier to long-context generalization. This raises a natural question:
"Is it possible to harness the inductive bias from positional embeddings exclusively during pretraining?"
It turns out the answer is yes! We propose a new method for extending the context of LMs by Dropping their Positional Embeddings after pretraining (DroPE). Following a short calibration phase on the original pretraining data, performed at the original context length, DroPE models perfectly reproduce the “in-context” performance of the base model. This simple procedure unlocks strong zero-shot context generalization to unseen sequence lengths, beyond highly-tuned RoPE extensions and alternative architectures.
Integrating DroPE in mid-training with no additional cost
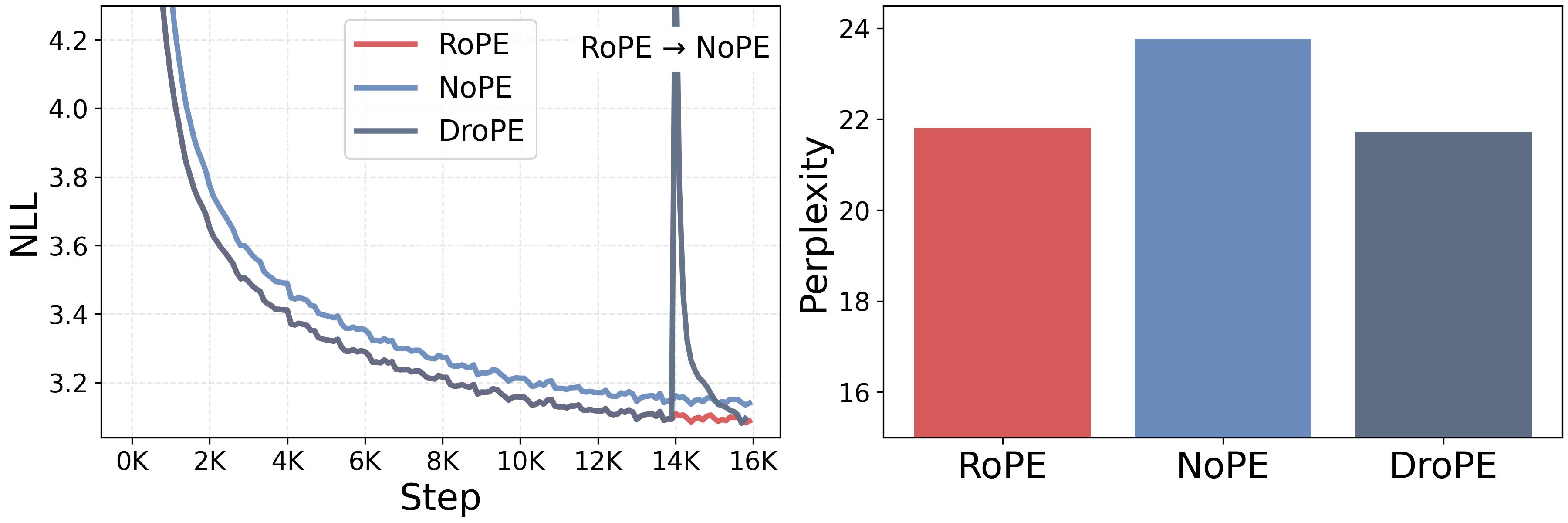
To demonstrate DroPE's performance as a zero-cost addition to pretraining, in our first set of experiments, we train from scratch different LMs with half a billion parameters on 16B tokens. We repeat this recipe for RoPE and NoPE transformers, as well as our DroPE variant. We implement DroPE by taking the 14B tokens RoPE transformer checkpoint, removing positional embeddings from every layer, and resuming training for the final 2B tokens. Despite only recalibrating at the very end of training, at no extra cost, DroPE matches the final in-context validation perplexity of RoPE trained on the full 16B tokens, and improves over the NoPE baseline trained without positional embedding all the way.
Applying DroPE to LMs "In the Wild"
For our second set of experiments, we directly apply DroPE to two language models from the SmolLM family with 360M and 1.7B parameters pretrained on up to a trillion tokens. We perform DroPE's recalibration with continued pretraining using the data and hyperparameters used to train SmolLM. We consider three different recalibration budgets of 30, 60, and 120 billion tokens, adjusting the learning rate schedule accordingly. We start by analyzing how quickly our SmolLM-DroPE models can recover SmolLM's in-context performance on LM reasoning benchmarks.
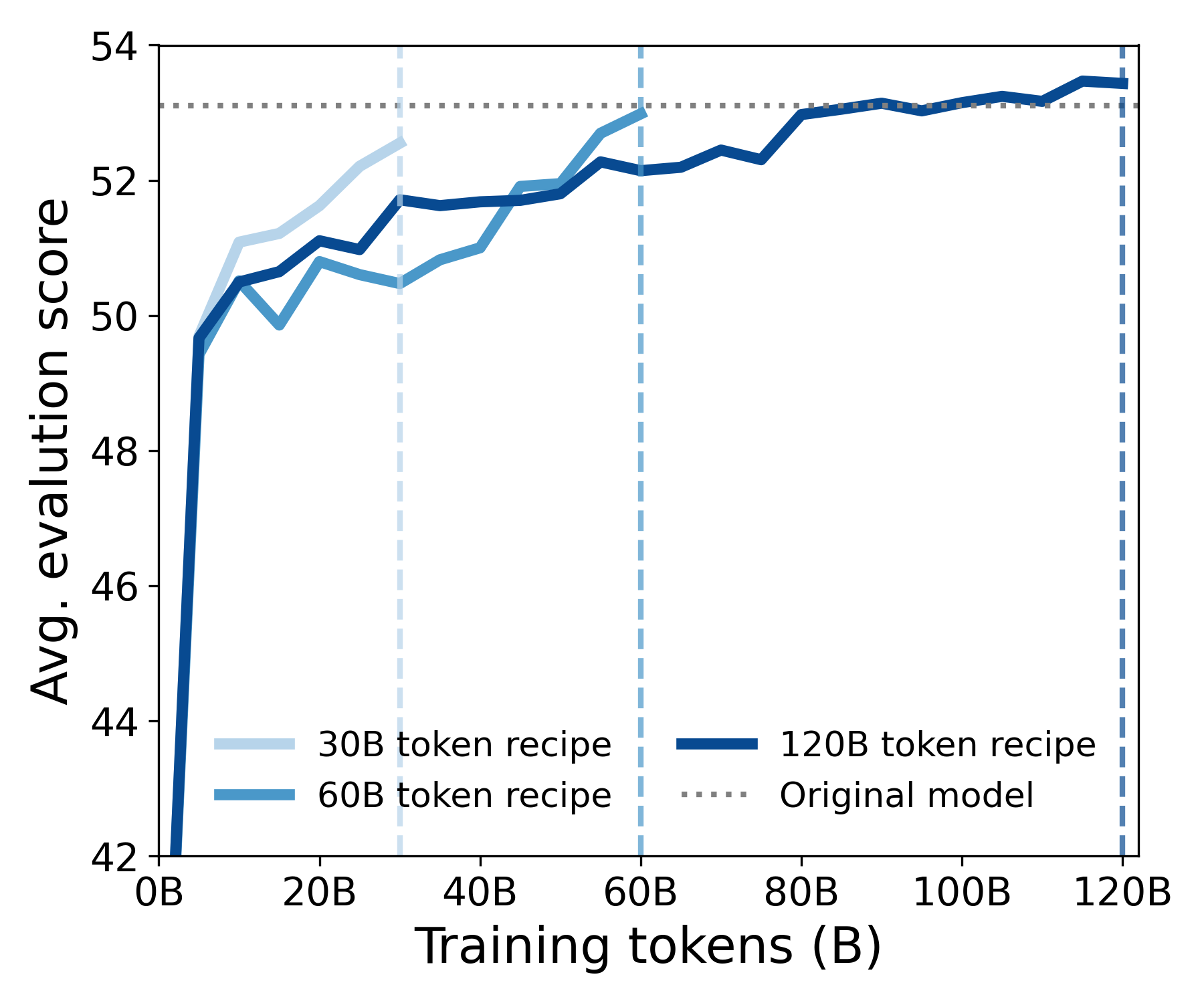
Even with our shortest training schedule, SmolLM-DroPE almost entirely matches the base model’s performance, while with our longest schedule, it manages to exceed original performance (no need to train for that long!). The same holds across SmolLM-360M and SmolLM-1.7B, suggesting that extending pretrained models with DroPE can be done efficiently with sublinear costs. Furthermore, we find that DroPE quickly recovers over 95% of SmolLM's performance after less than 5B tokens, representing a minuscule 0.8% of SmolLM's original budget.
Long-context evaluations
Evaluating long-context capabilities of models can also be complex. Performance on long-context tasks is affected
by many different factors, and there are many reasons LMs struggle with long sequences
Needle-in-a-haystack. One of the simplest ways to evaluate a model's ability to function when the
input context is extremely long is the needle-in-a-haystack (NIAH) task. This type of task comes in various shapes
and forms, but the basic idea behind all of them is to retrieve a specific piece of clearly identifiable
information (needle) from a long, irrelevant textual context (haystack). These are the types of tasks that would
be easily solved by, e.g., regex matching or other search techniques. We consider three types of NIAH variants
from the RULER benchmark
We evaluate our pretrained models on sequences twice as long as the ones they saw in training. We find that DroPE models substantially outperform both RoPE-scaling context extension baselines as well as different PE schemes.
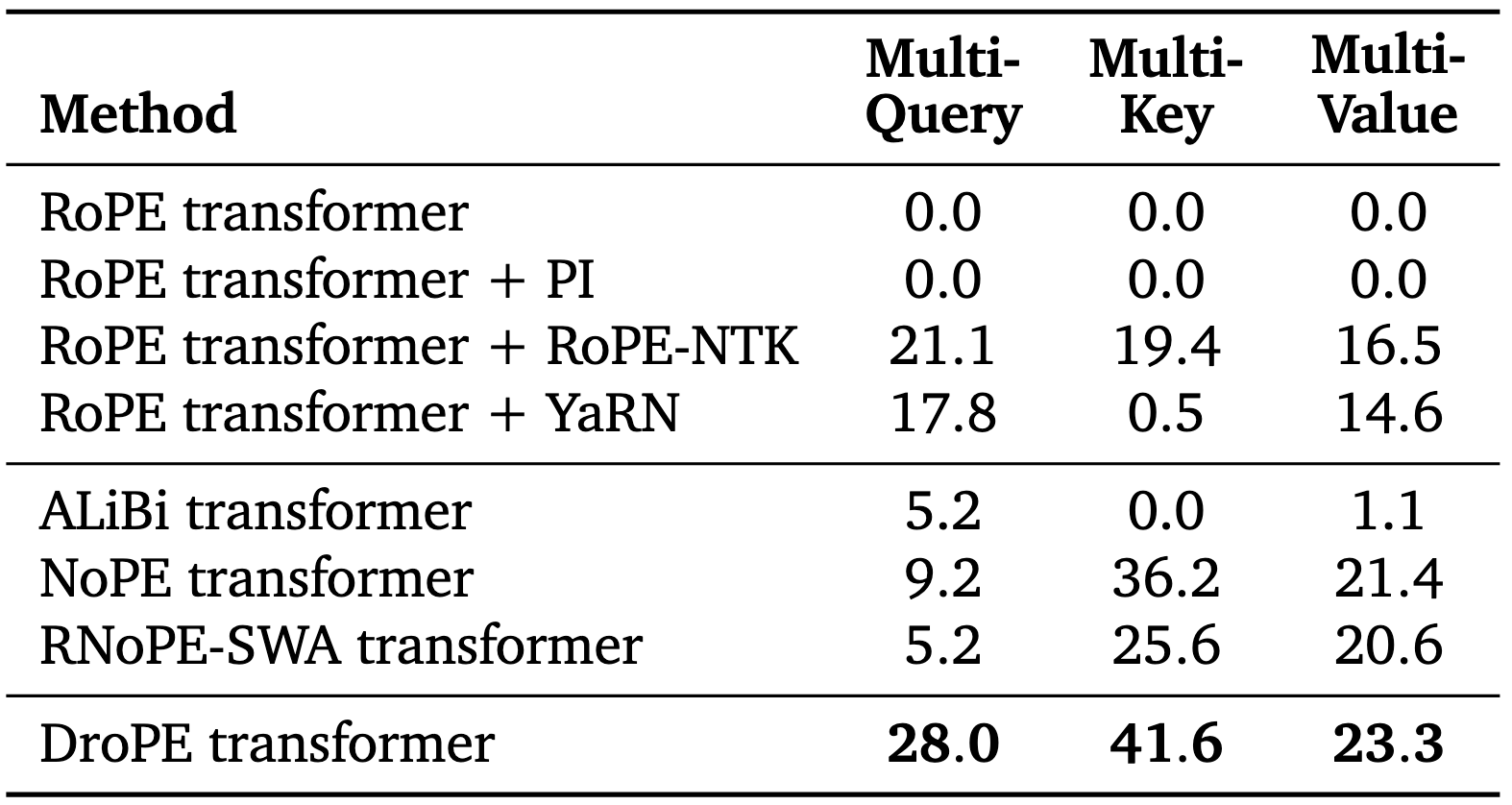
The gap between DroPE and context extension methods is most pronounced on the multi-key task. In contrast, specialized architectures underperform on multi-query tasks, which are the logic-intensive setting where strong base models excel.
LongBench. Additionally, we evaluate DroPE on general language tasks that require handling long contexts, such as summarization, multi-document question answering, and more. For these tasks, we evaluated DroPE applied to LMs in the wild, focusing on the SmolLM
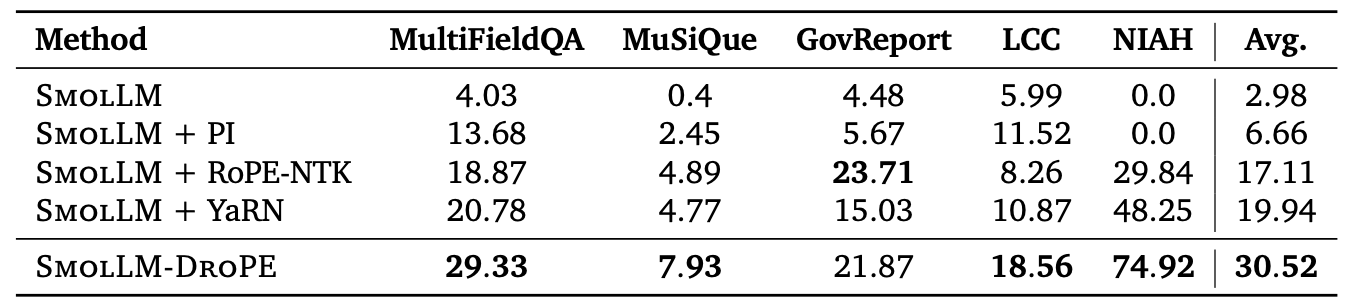
In this scenario, the only relevant baselines are context extension methods. LongBench is a challenging benchmark even for closed-source LMs, including knowledge-extraction problems longer than 80 times SmolLM's pretraining context (2048 tokens). Despite a significant difficulty spike compared to our prior evaluations, DroPE still displays a clear edge over prior approaches, improving the base SmolLM's average score by over 10 times.
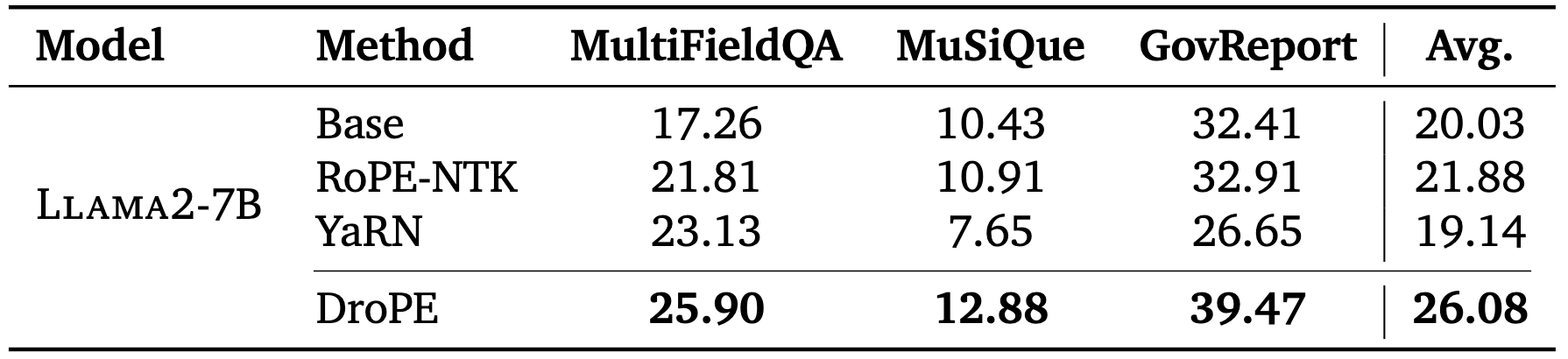
Scaling to 7B models
Given the remarkable efficiency of recalibration, we tested DroPE's ability to scale to larger LMs in the wild. We chose Llama2-7B, which is a dense 7B parameter model that was trained on 4 trillion tokens. We perform recalibration on 20B tokens, which represents only 0.5% of Llama2-7B’s pretraining budget. DroPE once again outperforms state-of-the-art RoPE-scaling methods on long-context question-answering and summarization, providing strong evidence towards scalability. These results demonstrate the immediate potential to integrate DroPE in modern pipelines.
Conclusion
In this work, we tackle a canonical bottleneck in long-context language modeling: positional embeddings are critical for training but prevent true length generalization. We propose a simple solution: use PEs to train your model, but then remove them and recalibrate to get a PE-free model that can generalize zero-shot. DroPE can be viewed both as an alternative pretraining recipe that does not have any additional cost, or as an inexpensive (down to only 0.5% of pretraining cost) adaptation method. DroPE outperforms current approaches—both context extension methods and tailored architectures—and is validated on models with up to 7B parameters, pretrained on trillions of tokens. We believe that DroPE can be integrated into modern pipelines at any scale and help to improve the way we train models for long-horizon tasks.