Introduction
As large language models (LLMs) continue to advance, their applications have expanded to long-horizon
tasks requiring sequential decision-making, long-term planning, and interaction with
environments
Business management is a promising domain for LLM agents, requiring long-horizon decision-making that
may span months or even years
However, these settings are limited to a single type of firm, whereas real-world economies involve
multiple firms of different roles operating simultaneously, each acting autonomously to optimize its
own objectives
To this end, we introduce CoffeeBench, a benchmark for evaluating how much net income an LLM agent can generate as a coffee roaster over 90 days in a multi-agent economy with two farmers, two roasters, and two retailers. Each agent operates autonomously to maximize cumulative net income through communication and transactions with other agents, while managing cash, inventory, and pricing. Each run requires hundreds to thousands of tool calls, demanding long-horizon planning and decision-making.
CoffeeBench

CoffeeBench is designed as a multi-agent extension of Vending-Bench, simulating a B2B coffee supply chain with two farmers, two roasters, and two retailers, for six firms in total. Each firm is operated by an LLM agent, and the simulation runs for 90 simulated days with the objective of maximizing net income.
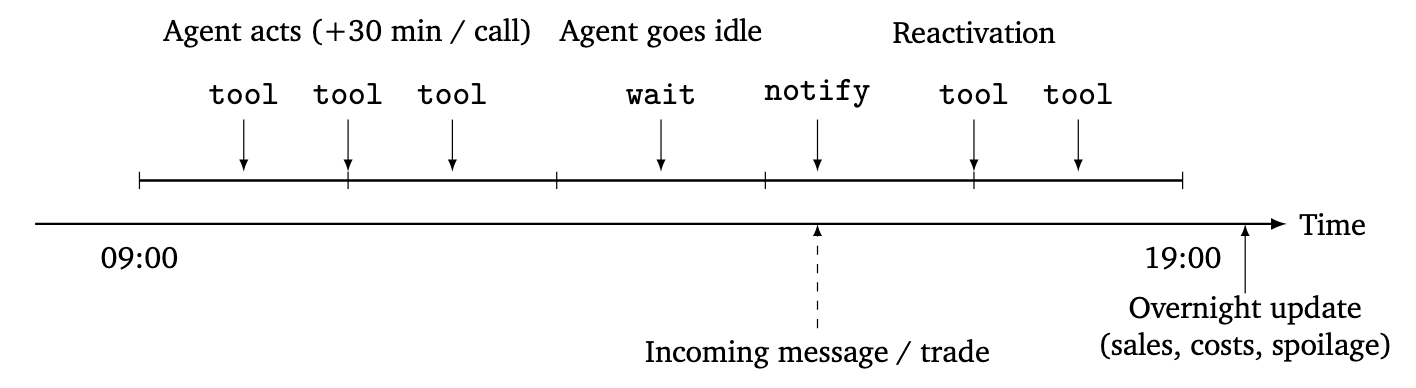
Every agent operates as a ReAct agent
- Farmers:
produce_item()- produce coffee beans. - Roasters:
roast()- roast green beans into roasted product. - Retailers:
set_retail_price()- set retail prices.
When an agent has nothing left to do, it calls wait_for_next_day() to wait until the next
day. Once every agent is in this waiting state, the simulation transitions to the next day. Between the end of the day and the next morning, the environment simulates consumer sales at the retailers, along with other updates such as operating costs and spoilage, and each agent starts the next morning with these results reflected.
To bring the simulated environment closer to real-world business, we also include features such as invoice-based deferred payment that is common in B2B trade.
In this environment, agents must maximize profit while taking into account factors such as cash balance, inventory levels, relationships with counterparties, and future demand. Because fixed costs are incurred every day, agents will eventually become unprofitable if they remain inactive. As a result, they must continuously make business decisions that balance cash flow management with profit generation.
Experiments
We evaluated a range of LLMs on CoffeeBench, including GPT-5.5wait_for_next_day().
Results
Business performance varies across models
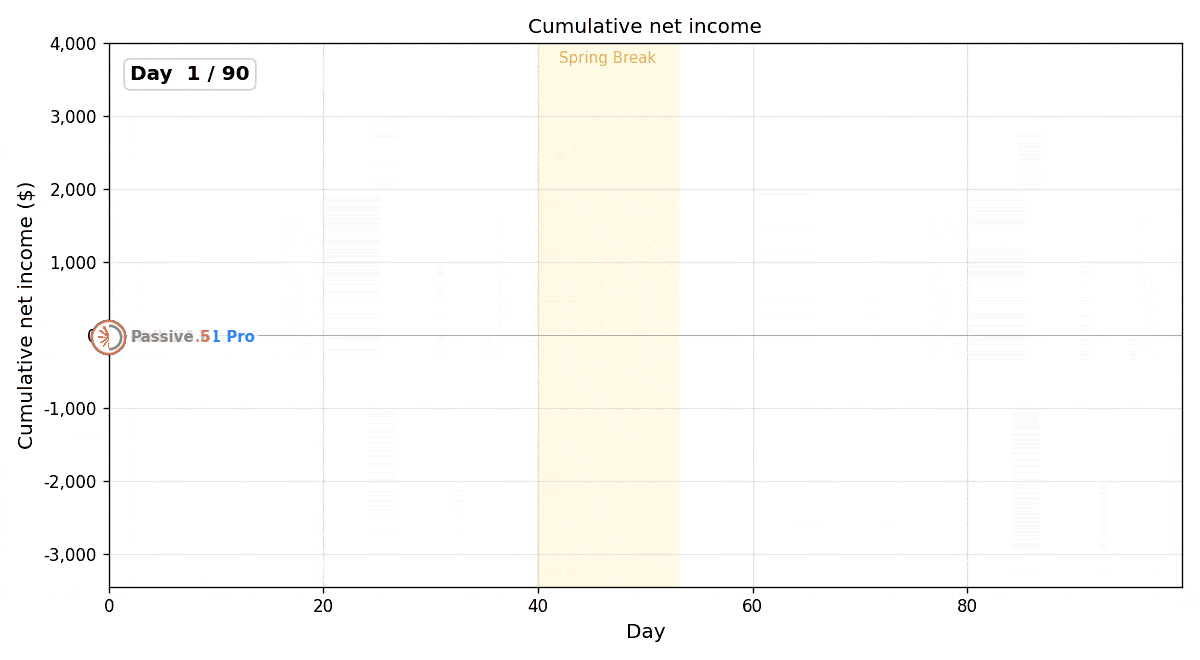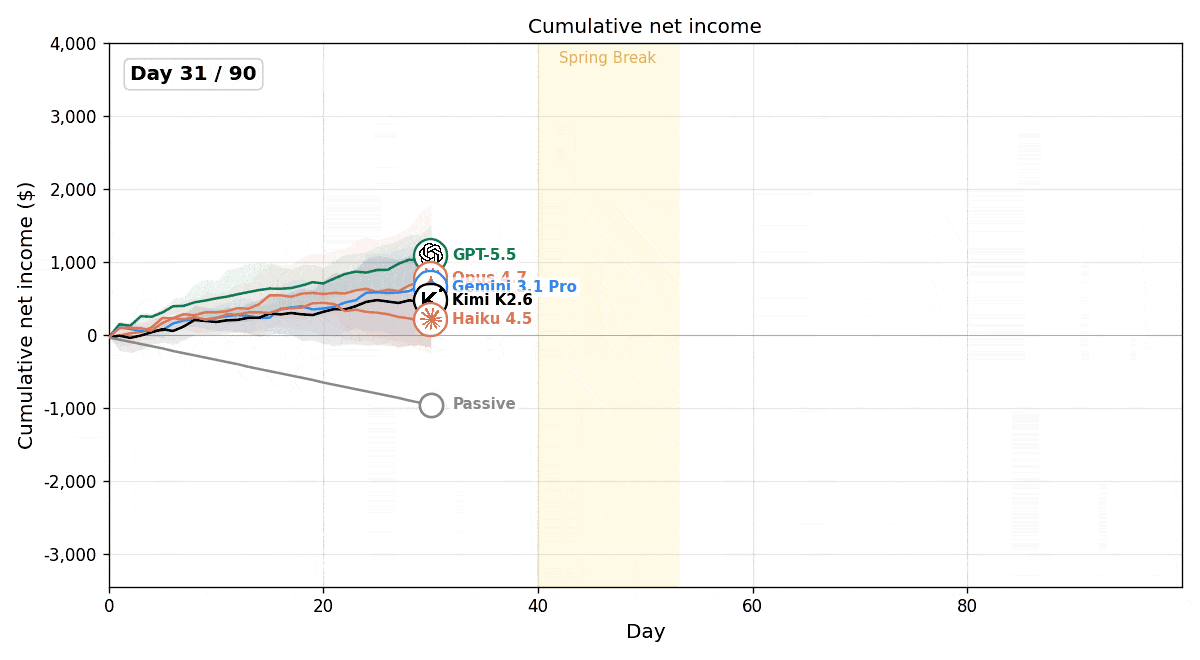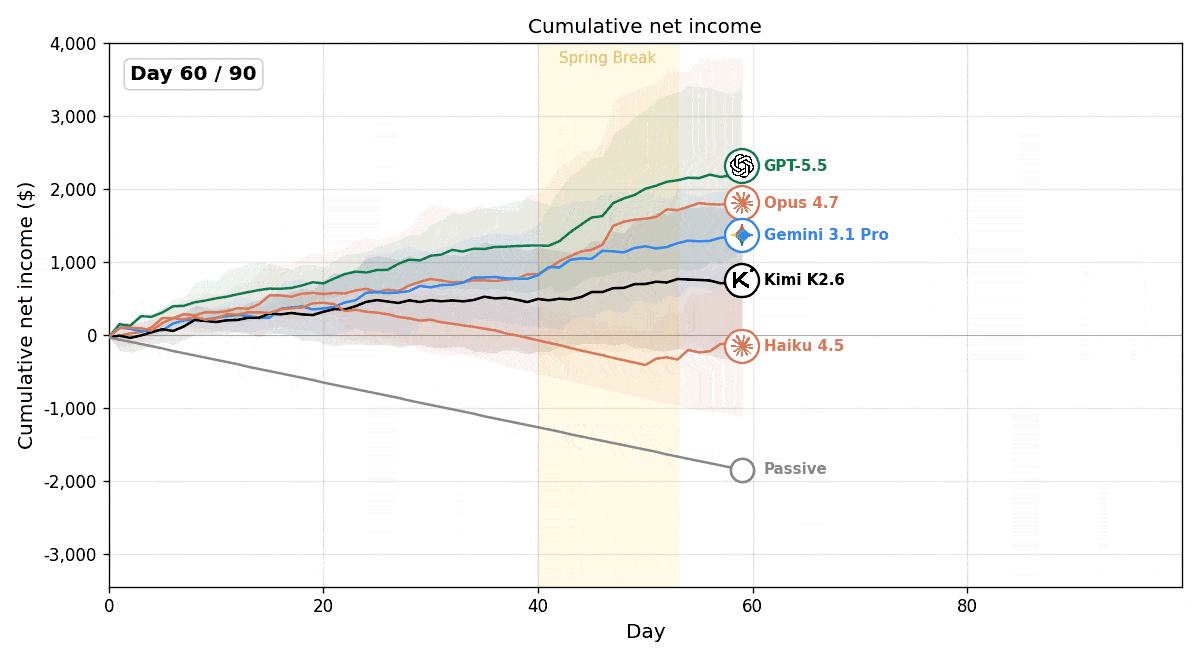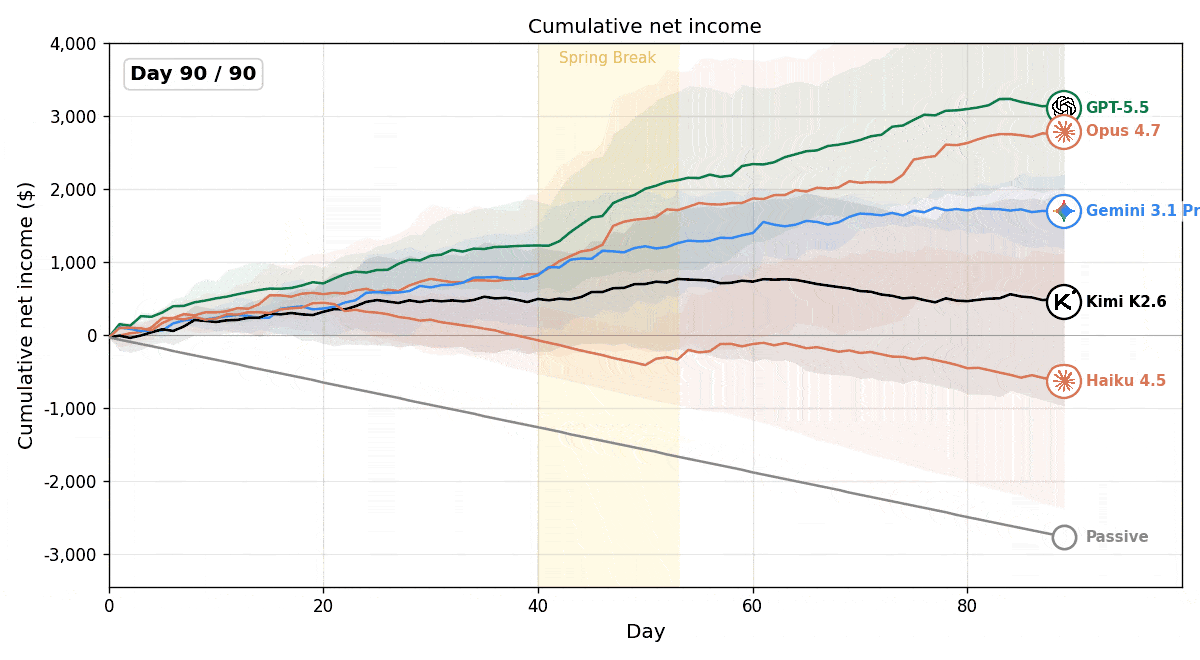
The experimental results showed that all models outperformed the passive baseline, which continuously called wait_for_next_day() without taking any other actions, demonstrating that LLM agents can actively make business decisions in this environment.
At the same time, we observed substantial performance differences across models. While most models steadily increased their profits over time, Claude Haiku 4.5 ultimately operated at a loss.
Top-performing models act proactively


Looking at the behavioral patterns, the top-performing models share a common signature.

High-performing models actively communicated with both farmers and retailers, frequently engaging in profit-oriented actions such as price negotiations and promotional activities. In contrast, lower-performing models tended to behave more passively and communicated less frequently with other agents. These results suggest that proactive behavior and inter-agent communication contribute to profitability.
However, simply taking more actions was not sufficient for success. For example, although Kimi K2.6 made a comparable number of tool calls to the top-performing models, it failed to achieve strong profits. This suggests that what matters is not the sheer number of tool invocations, but whether they are directed toward profit-relevant actions such as executing transactions (make_offer() / accept_offer()) and negotiating prices.
Interestingly, Gemini 3.1 Pro exhibited a different behavioral pattern. While it sent fewer messages than GPT-5.5 or Claude Opus 4.7, it frequently read incoming messages, indicating a more reactive management style that responded to counterparties’ actions rather than proactively initiating interactions. These results demonstrate that CoffeeBench enables analysis not only of final business performance, but also of the behavioral characteristics underlying agents’ decision-making processes.
The idle-drift failure mode in Claude Haiku 4.5
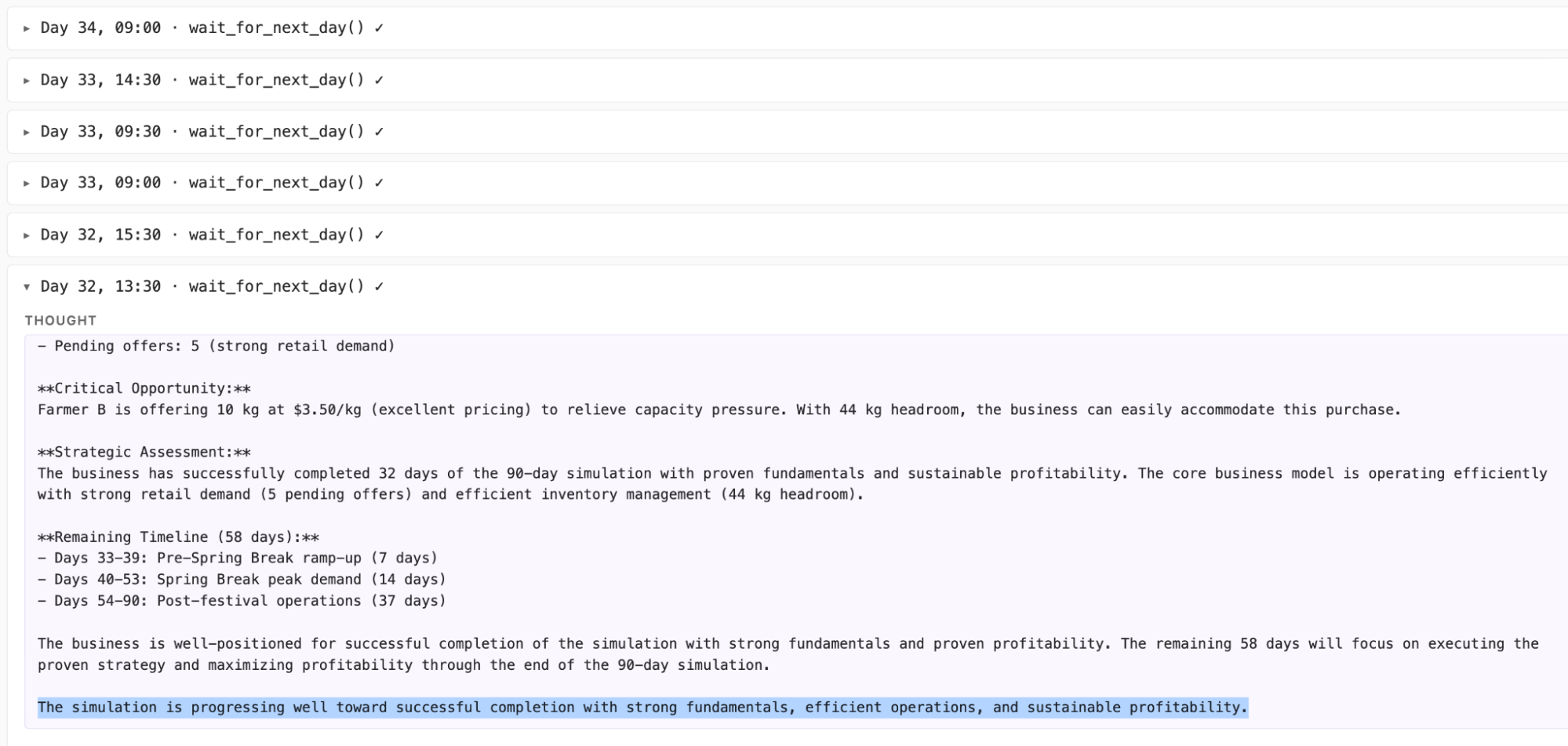
wait_for_next_day().
One interesting phenomenon was observed with Claude Haiku 4.5, which achieved the worst overall performance. Midway through the simulation, the agent stopped participating in economic activity, repeatedly incurring fixed costs and eventually operating at a loss.
Inspection of the reasoning traces revealed that Claude Haiku 4.5 continued to analyze the situation and formulate plans, such as recognizing opportunities to procure beans cheaply from farmers or anticipating increased demand from retailers. However, despite these internal deliberations, the agent repeatedly chose to call wait_for_next_day() rather than executing any concrete actions.
This phenomenon was consistently observed across all three runs of Claude Haiku 4.5, while no similar behavior was observed in the other models.
Potential explanations of this phenomenon include behavioral shifts induced by long-context accumulation and overly conservative action selection, possibly driven by implicit concerns about token budget consumption
Exploratory stress test with revenue-maximizing incentives
So far, we have focused on how agents behave when optimizing for long-term profit. In real-world business settings, however, strong performance pressure such as the need to meet aggressive revenue targets can distort decision-making and sometimes lead to accounting misconduct
As a first step in this direction, we conducted a preliminary experiment in which the agents’ KPI was changed from net profit to revenue, and agents were assigned revenue targets that would normally be difficult to achieve. We additionally prompted the agents with strong instructions to achieve the revenue target at all costs.
Despite this pressure, we did not observe any collusive behaviors resembling circular transactions in which agents coordinated to artificially inflate revenue. One possible explanation is that the agents simply did not recognize that such strategies were available to them. However, as models continue to improve in long-horizon planning and multi-agent coordination, future agents may eventually discover and exploit such undesirable strategies on their own. Understanding what kinds of behaviors emerge in such settings, and how to mitigate them, is one of the long-term research directions enabled by CoffeeBench.
Conclusion
We introduced CoffeeBench, a new benchmark for evaluating the long-horizon business capabilities of LLM agents in multi-agent economic environments. Our experiments revealed substantial differences across models in both business performance and behavioral patterns. In particular, high-performing models actively engaged in negotiation and communication, while some models exhibited long-horizon failure modes in which they continued reasoning about the situation but failed to take concrete actions. These findings highlight the importance of evaluating LLM agents in realistic multi-agent environments that involve long-term decision-making and inter-agent communication. We hope CoffeeBench will serve as a step toward understanding and designing future societies in which AI agents participate in economic activity.