DiffusionBlocks: Training Neural Networks One Block at a Time
Summary
Modern AI shows remarkable performance across everyday tasks, math, coding, and more. Today's frontier models typically have hundreds of billions of parameters or more and require thousands of GPUs to train, and only a small number of organizations have the resources to develop them.
One major reason for these resource demands lies in the training method itself. Today's neural networks, including Transformers
Motivated by this, we propose DiffusionBlocks, a method that divides a network into multiple blocks and trains only one block at a time, with each block learned independently of the others. As a result, training requires memory for only a single block rather than the entire network. At the same time, performance remains competitive with end-to-end optimization, achieved through a diffusion framework, which has seen tremendous success in recent years. Our experiments demonstrate this across architectures spanning image classification, image generation, and text generation.
This is joint work with Masanori Koyama (The University of Tokyo) and was presented at ICLR 2026, a top international conference in machine learning. The full paper is available below:
- Paper: https://arxiv.org/abs/2506.14202
- OpenReview: https://openreview.net/forum?id=pwVSmK71cS
Background: The Memory Bottleneck in Deep Learning
Modern AI has been driven by scaling: the empirical observation that performance improves as model size and training data grow
To see why memory grows with the size of the network, consider how networks are trained. They are typically trained with end-to-end backpropagation, which requires keeping all intermediate states (activations) across the network in memory. As a result, memory consumption grows linearly with the depth of the network. Since modern Transformers are scaled in large part by adding more layers, depth directly drives the growing memory cost.
Block-wise Training in Practice
One natural solution to this problem is block-wise training. If we partition the network into smaller blocks and train each independently, the memory required during training drops to that of just one block at a time.
A line of prior work has explored this direction
NoProp
This effort led to DiffusionBlocks, which we introduce next.
Our Method: DiffusionBlocks
In standard neural network training, the goal is essentially to learn the mapping from input to target. What each layer does along the way is left unspecified, and the layers are treated as a black box that "somehow coordinates to connect inputs to outputs."
In contrast, DiffusionBlocks explicitly assigns a role to each block (a group of layers), so that the network as a whole accomplishes its overall goal of producing the target. Each block only needs to optimize toward its own individual objective, and can be trained without depending on what the other blocks are doing.
In particular, the role we assign to each block is the dynamics of "gradually approaching the target as we move through the blocks." This matches the essence of diffusion models
This connection builds on prior work: residual connections correspond to discretized steps of an ordinary differential equation
Once we interpret the block-wise dynamics as a diffusion process, each block can be trained independently in a theoretically principled way. This is the core idea behind DiffusionBlocks.
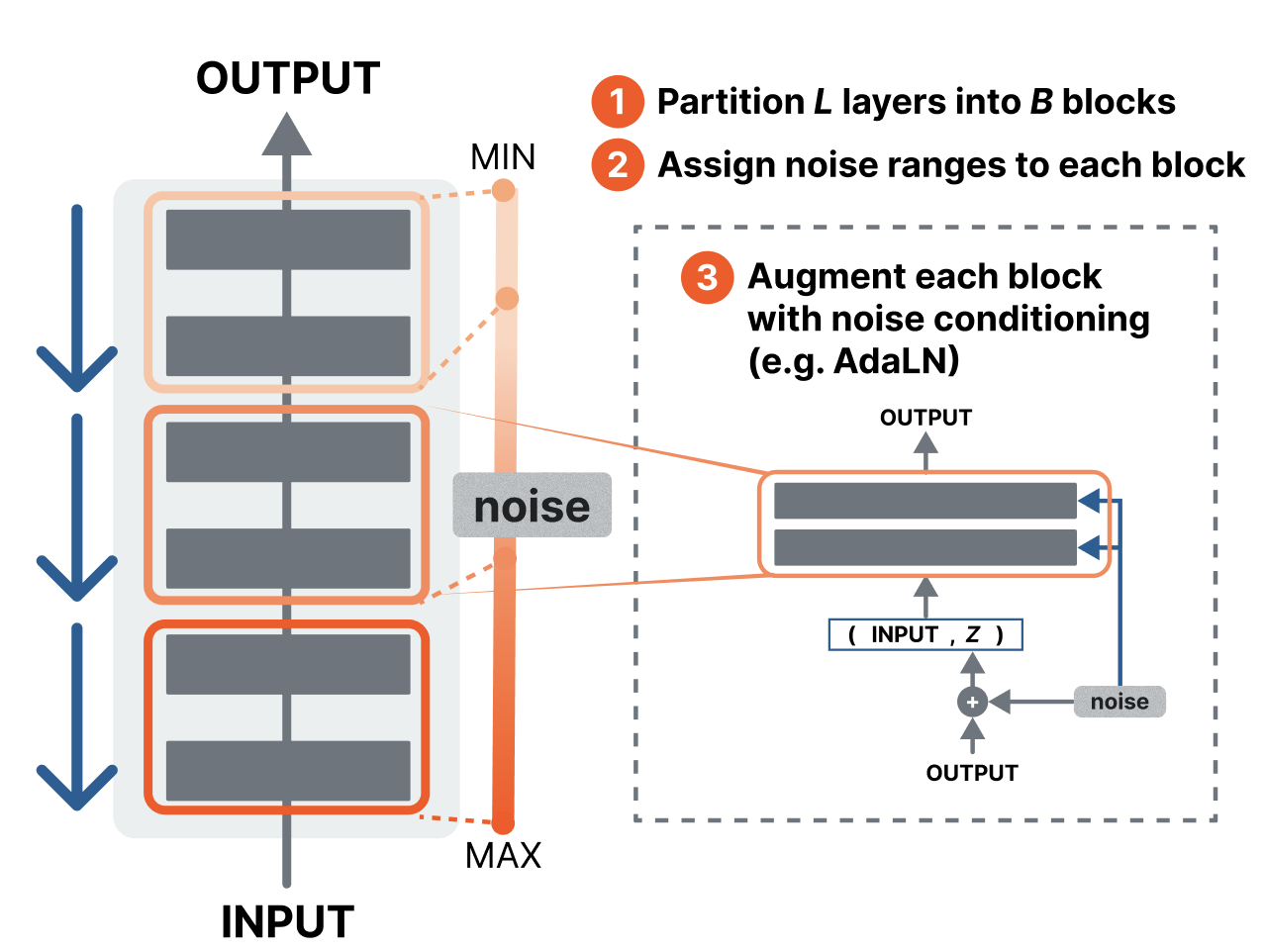
Converting an Existing Network in 3 Steps
Converting a standard Transformer-based network into a block-wise trainable model requires just three modifications:
- 1 Partition. Split the L layers into B blocks.
- 2 Assign noise ranges. Each block is responsible for a range of "closeness to the target."
- 3 Add conditioning. A conditioning module lets each block recognize its assigned range.
During training, it suffices to randomly sample a single block at each iteration. Since the other blocks do not need to be computed, memory consumption is reduced to roughly 1/B. We refer the reader to the paper for technical details, including the equations and architecture-specific adaptations.
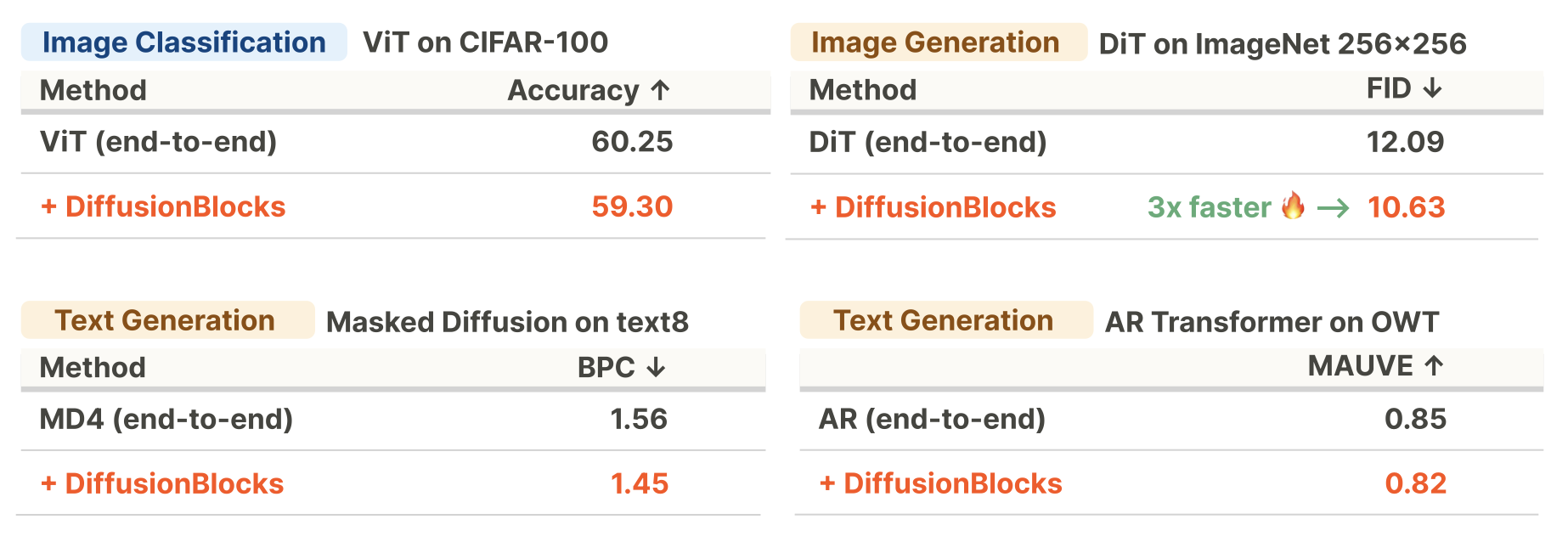
Validation Across 5 Different Architectures
To demonstrate that DiffusionBlocks is a versatile training framework, we validated it across three task domains using five different architectures: image classification (ViT
In all cases, DiffusionBlocks achieved performance comparable to end-to-end training while reducing memory usage.
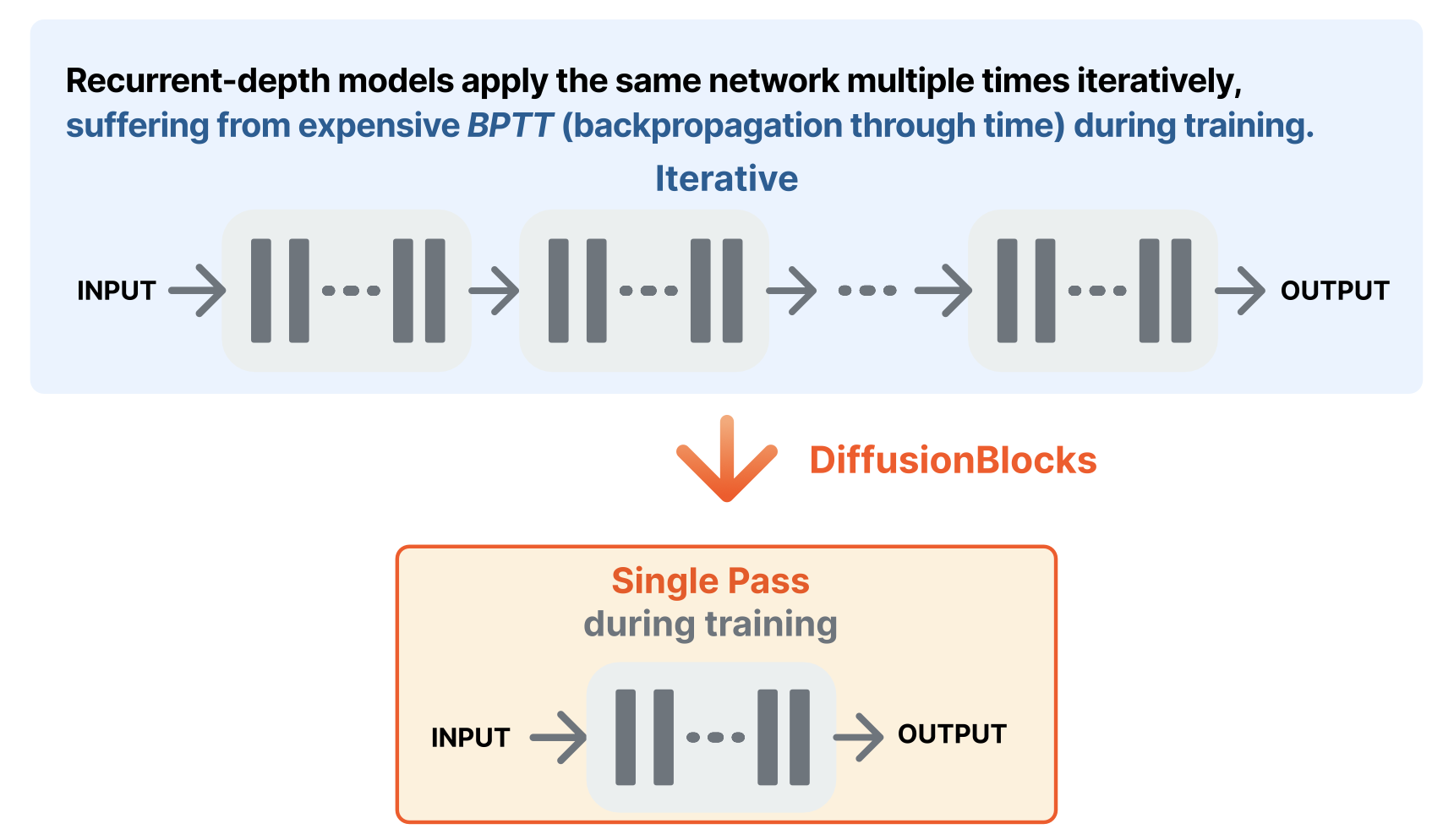
Beyond Block-wise: Efficient Training for Recurrent-depth Models
The DiffusionBlocks perspective naturally extends to Recurrent-depth models (also known as Looped Transformers)
A Recurrent-depth model is an architecture that applies the same network times iteratively. Training such models requires backpropagation through time (BPTT), which has been a major computational bottleneck.
From the DiffusionBlocks perspective, the recurrent-depth dynamics of repeatedly applying the same network to progressively refine the output matches the "gradual progress toward the target" that DiffusionBlocks captures. As a result, we can replace -iteration BPTT training with a single forward pass during training, significantly reducing computational cost without sacrificing performance.
Future Works
To close, we highlight two particularly important directions for future research on DiffusionBlocks.
Theoretical analysis of why memory efficiency and performance can both improve.
In our experiments, we observed several cases where DiffusionBlocks not only achieves lower memory consumption but also outperforms standard end-to-end training. A formal analysis of this effect could yield new insights into the design of neural network training itself. Our hypothesis is that explicitly assigning each block a role may give rise to a natural form of curriculum learning
Extension to pretrained large-scale models. So far, we have validated DiffusionBlocks on networks trained from scratch. However, we believe the largest practical impact lies in converting existing pretrained large-scale models into DiffusionBlocks via fine-tuning. If this proves feasible, training and downstream use of large-scale models would become practical not only for well-resourced organizations but for individual researchers, students, and smaller labs.
DiffusionBlocks is part of Sakana AI's broader effort to make AI more efficient. This effort includes evolutionary model merging, model ecosystems via natural niches, knowledge distillation, inference-time memory optimization, low-cost context extension, kernel-level training and inference acceleration, and others. DiffusionBlocks adds a new axis: the memory consumed during training itself.
We hope this work opens a useful path in that direction. Please read the full paper for further details.