Sparser, Faster, Lighter Transformer Language Models
tl;dr
In collaboration with NVIDIA, we introduce new sparse data structures and GPU kernels to leverage unstructured sparsity for efficient inference and training of LLMs. This work will be presented at ICML 2026.
Summary
Modern large language models (LLMs) are powerful. They can write code, reason through complex problems, and synthesize vast amounts of technical knowledge. However, providing such capabilities at scale comes with tremendous real-world costs.
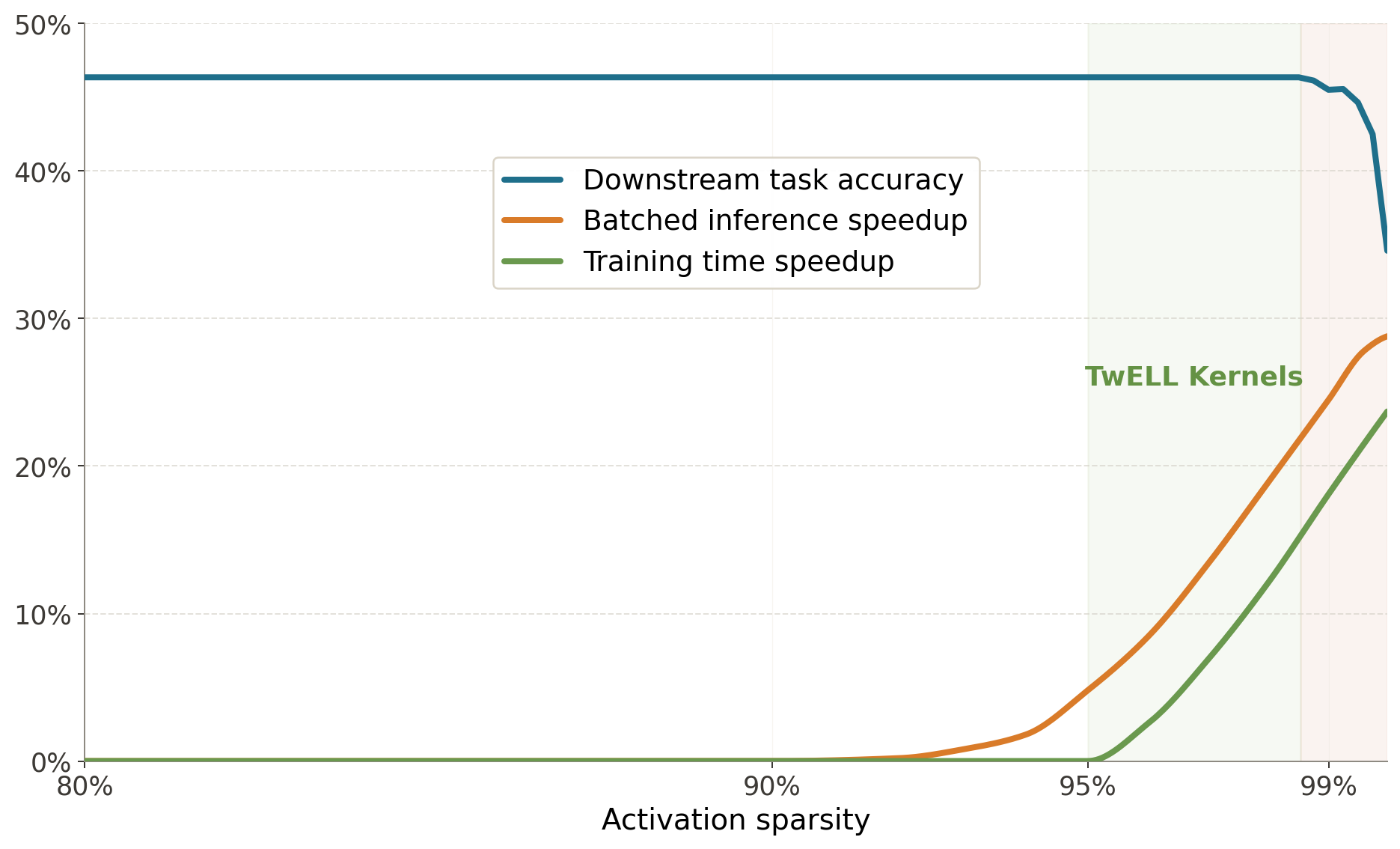
A large part of these costs comes from the feedforward layers, a ubiquitous component of LLMs since their inception. Yet, inside these layers, an interesting phenomenon can be observed: For any given token, only a small fraction of the hidden activations actually matter, with the rest effectively approximating zero and wasting computation. With ReLU and L1 regularization, this sparsity can be even made to exceed 95% with little to no impact on downstream performance
So, can we leverage this sparsity to make LLMs faster and lighter?
The difficulties of achieving this objective lie in the hardware. Modern NVIDIA GPUs are extraordinarily good at homogeneous workloads, with specialized units dedicated to dense matrix multiplications. Traditional algorithms for efficiently leveraging unstructured sparsity clearly do not fit these assumptions, and introduce non-trivial constant overheads and bookkeeping that cancel out their theoretical savings.
This work, a collaboration between Sakana AI and NVIDIA, is about resolving this paradox:
- First, we introduce a new sparse packing format, called TwELL (Tile-wise ELLPACK), designed specifically to integrate with the tiled matrix multiplication kernels that power modern accelerators without disrupting execution pipelines or introducing additional memory overhead.
- Second, we develop a new set of custom CUDA kernels for both LLM inference and training, fusing multiple matrix multiplications to maximize throughput and compressing TwELL to a sparse representation that trivializes storage costs.
To substantiate these gains, we study sparse LLMs at billion-parameter scales and show that mild L1 regularization can induce high levels of sparsity after training with negligible impact on downstream performance. By leveraging our kernels, these sparsity levels translate into over 20% speedups for both batched inference and training on H100 GPUs, while also cutting energy consumption and memory requirements.
Get ready for a deep dive into GPUs, LLMs, and sparsity!
Transformers and Feedforward Layers
At a high level, the "body" of modern transformers is composed of a repeated stack of just two components: an attention block (linear or quadratic), followed by a feedforward block. While attention lets tokens communicate with each other, the feedforward block processes each input token independently, performing multiple matrix multiplications with a set of large learned weight matrices.
Formally, a modern feedforward block takes as input a matrix , where is the total number of tokens (number of batched sequences sequence length), and is the token embedding size. The input is then multiplied by three different weight matrices to first expand this representation into a much larger hidden space of size , apply a simple non-linearity, and then project it back down for the next block. Formally, this computation looks as follows:
Here, are commonly referred to as the weight matrices for the "up" and "gate" projections, and as the weight matrix for the "down" projection. The non-linearity , such as SiLU or ReLU, is what introduces sparsity in the gate activations , which is carried over to the hidden activations following the elementwise product . As the hidden dimension is typically much larger than (often 4x or more), these layers can often be responsible for the majority of both parameters and FLOPs in modern LLMs.
In this overparameterized regime, prior work has shown that pretrained transformers with ReLU activations can already exhibit high levels of unstructured sparsity in their feedforward blocks
GPUs, Memory, and Tiling
To understand the challenges of leveraging sparsity to accelerate matrix multiplication, we provide a brief primer on how modern GPUs execute programs and the hardware characteristics.
Whenever executing any code on an NVIDIA GPU using PyTorch or any other library, this launches a GPU kernel, a massively parallel program executed across many threads on the device. The kernel's computation is first distributed across a grid of many independent units of work called cooperative thread arrays (CTAs)A CTA is also commonly referred to as a thread block in several tutorials and books.. Each CTA is scheduled on a single Streaming Multiprocessor (SM)An SM is the GPU execution unit that schedules and runs CTAs, somewhat analogous to a CPU core but built for massive parallelism. and consists of many threads working together to carry out the kernel operations on a set portion of the input data. This design allows the same optimized kernel, written from the perspective of the threads in a single CTA, to be easily ported to different input sizes by simply scaling the number of CTAs in the grid. The threads in the CTA are not entirely independent of each other but are grouped into units of 32 called warps, which execute the same instructions at each clock cycle on different inputs. All these constraints help reduce the cost and chip-space dedicated to each execution unit and enable GPUs to achieve massive parallelism: thousands of threads are scheduled across many CTAs, all performing arithmetic and memory operations concurrently.
However, not all operations are equal. As theoretical FLOPs on modern NVIDIA devices have risen dramatically in recent years, the bottleneck of many common kernels is often memory bandwidth.
Modern GPUs have a hierarchical memory system with three distinct levels. At the bottom level, we have a global memory available to all threads running on the GPU and residing separately from the compute units on a stack of high-bandwidth memory (HBM). While global memory can be large (80GB for an H100 GPU), it comes with high latency on the order of ~500 cycles and limited per-device bandwidth. Surrounding the compute units themselves, on the second level, we have on-chip shared memoryShared memory and registers are built from SRAM, which is extremely fast but physically large and expensive per bit.. Shared memory is much faster, with latencies closer to ~10–20 cycles and is private to each CTA. At the top level, we have on-chip register memory which can be accessed in a single cycle and is private to each thread. Moving up the hierarchy, each level becomes over an order of magnitude faster, but correspondingly smaller due to the physical constraints of on-chip storage. For instance, while an H100 GPU provides 80GB of HBM, each CTA is limited to at most 228KB of shared memory, and each thread to only a few kilobytes of register storage.
Thus, designing efficient kernels requires minimizing accesses to global memory. This is directly reflected in the design of modern matrix multiplication kernels. Suppose we want to compute , where and . Each output element in this operation can be seen as an independent dot product:
An intuitive but suboptimal approach to implement this operation would distribute work across threads at the granularity of individual output elements. For instance, each thread could be assigned a single output element , load the row of and column of from global memory, perform the dot product, and store the results. The main issue with this approach is that it requires two separate loads for and before each partial accumulation. As a result, the same values of and are redundantly reloaded across many different threads, leading to a large number of expensive global memory transactions that dominate execution time.
Modern GPU kernels avoid this by using tiling. Instead of each thread operating on individual output elements, computation is reorganized by having the threads in each CTA cooperatively compute a separate tile of the output of shape . With this approach, each CTA iterates over the reduction dimension in chunks of size , and at each step all its threads cooperatively load a tile of of shape and a tile of of shape from global memory into shared memory.
Once both input tiles are loaded in fast shared memory, the threads in the CTA can reuse them to perform all necessary multiply-accumulate operations, updating a full tile of the output and storing it back at the end:
This reorganization allows amortizing the cost of each global memory load over many arithmetic operations: each element of is reused across output columns, while each element of is reused across output rows. As a result, the ratio of computation to memory traffic or the kernel's arithmetic intensityArithmetic intensity can be calculated as FLOPs performed / bytes moved to and from global memory. increases dramatically, which can often shift the computation from being memory-bound to compute-bound.
The hardware of modern GPUs has increasingly specialized to support tiling. Many common GPUs have dedicated hardware units called Tensor Cores, with which warps can cooperatively issue matrix multiply-accumulate operations that execute asynchronously on whole tiles of data stored in shared memory, achieving extremely high throughput. On modern devices like the H100, this is further complemented by the Tensor Memory Accelerator (TMA), which enables asynchronous loading and storing tiles of data across global memory and shared memory and allows pipelining expensive data transfers with compute.
TwELL: a Sparse Format for Kernel Fusion
In this work, we introduce new sparse data formats designed specifically for integration with the feedforward blocks of LLMs during training and inference.
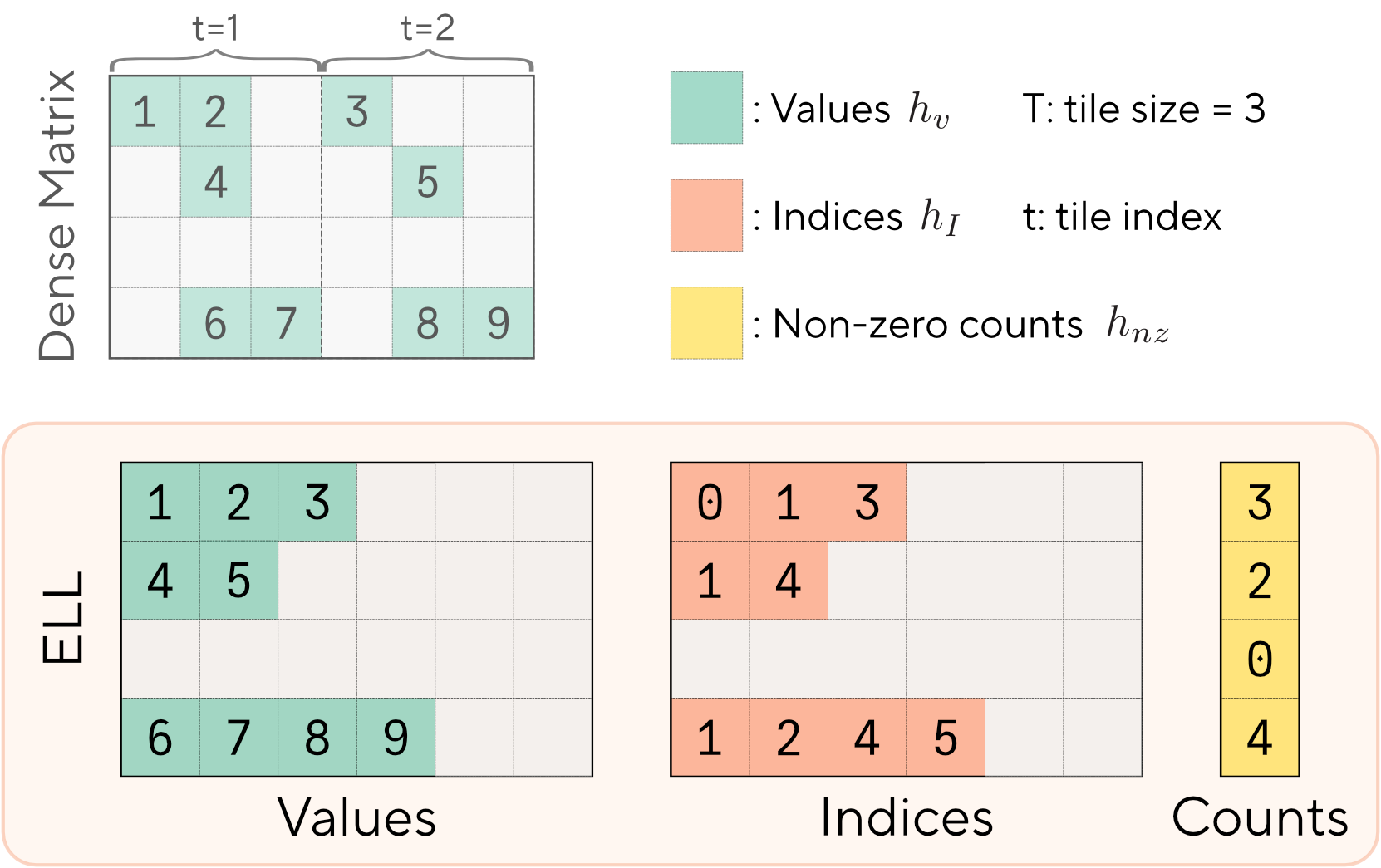
A natural starting point for exploiting unstructured sparsity in the activations is the ELLPACK format (ELL)
As introduced in the previous Section, one recurring principle in designing optimized kernels on modern NVIDIA devices is to minimize global memory accesses. Thus, let us consider a gated feed-forward block where sparsity patterns are determined by the gate activations . In this setting, representing with sparse formats such as ELL suffers from an immediate downside: constructing the format requires examining all elements in each row of to identify, count, and align the non-zero values and their indices. Ideally, we would want to avoid launching a separate kernel to convert the activation, which would introduce additional global accesses and overheads by fusing the two operations. However, ELL's row-wise packing structure is fundamentally misaligned with the tiled execution of modern dense matmul kernels, preventing direct fusion without expensive synchronization across CTAs.
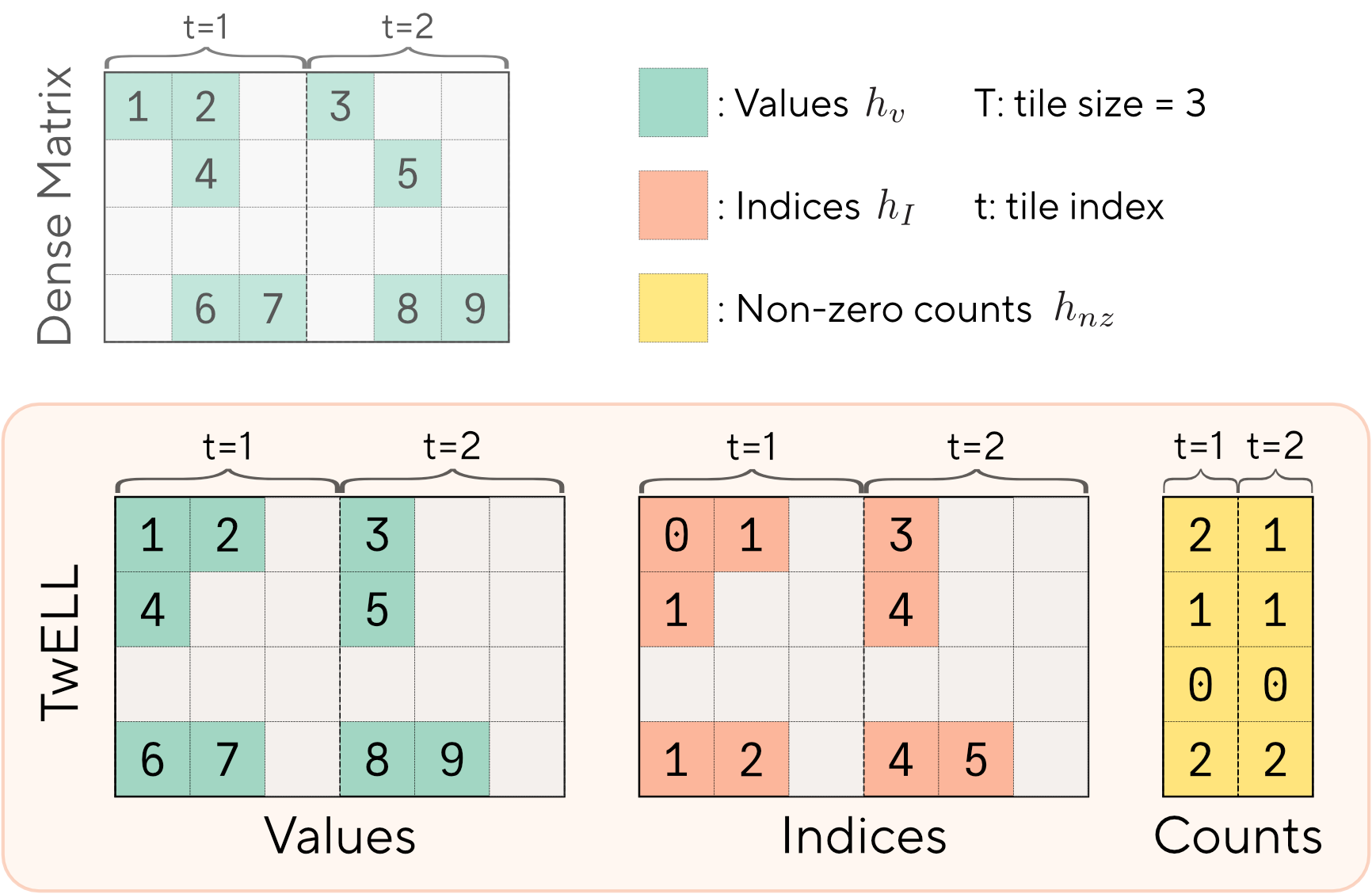
To address these limitations, we introduce TwELL. Rather than packing data across whole rows, TwELL partitions the columns of into horizontal tiles of size and stores the non-zero values and indices within each tile using a local ELL-style layout. This results in two packed matrices containing locally aligned values and indices , where is a compression factor chosen so that is larger than the maximum number of non-zeros in any tile to avoid storage overflow. Akin to modern ELL variants, in our implementation of TwELL, we also store an additional matrix with the number of non-zero elements with as many columns as total tiles. The key advantage of this design is that it inherently matches the computation structure of tiled matrix multiplication kernels. By choosing , each CTA can directly construct the TwELL representation for its tile of before the results are written back to global memory, eliminating the need for synchronization, extra kernel launches, and additional memory accesses.
We implement two different kernels precisely fitting this design to perform fused dense-to-sparse matrix multiplication, which only differ in the storage structure of the TwELL activations. After obtaining and converting the output, the first kernel simply stores the tiles for , , and within three separate output matrices. The second kernel instead packs the TwELL activations into a single compacted 32-bit matrix for better data locality, with the first entry of the output tile containing the number of non-zeros and each subsequent entry encoding the 16-bit non-zero value together with its corresponding 16-bit column index. Our kernels are written entirely in CUDA and combine other modern techniques such as persistency, pipelining, and advanced swizzling, making them even slightly faster than optimized dense-to-dense implementations in PyTorch and CuDNN.
Kernels to Efficiently Leverage LLM Sparsity
We leverage the sparse gate activations in our optimized TwELL formats via a set of highly efficient CUDA kernels specialized for batched LLM inference and training.
For batched inference, we design a single CUDA kernel to perform the rest of the computation in the feedforward block, leveraging sparsity to efficiently fuse the up and down projections together. Each CTA in the kernel handles a separate row and loads the input values in register memory at the beginning of the computation. The fused matrix multiplications are executed by traversing over the sparse gate activations with two nested loops: the first one over the number of column tiles and the second one over the corresponding number of non-zeros in each tile . For each non-zero activation at index , the CTA collectively loads the column of and row of to perform a dot product, followed by a scalar-vector product, and accumulates its results directly into the output .
This design avoids the materialization of the dense hidden activations and skips all unnecessary computation and global memory accesses, loading only the weight entries corresponding to active hidden dimensions. We structure our kernel by assigning a single warp of 32 threads to each CTA, maximizing concurrency across the grid. In turn, this provides improved cache locality together with fast data exchanges and accumulations via warp-shuffling instructions, allowing performance to scale naturally with increasing sparsity.
For training, we design a set of CUDA kernels to minimize the storage size of the sparse activations and lower the cost of memory traffic and gradient computation throughout the backward pass. To this end, our first kernel converts the gate activations from TwELL to a lightweight hybrid representation by fusing together the locally aligned tiles in each row into a single globally aligned matrix with a tight cap on the maximum number of stored non-zero values per row , while routing the small number of overflow cases into a dense backup matrix . Building on this representation, we implement additional CUDA kernels for optimized hybrid-to-dense and dense-to-hybrid matrix multiplications together with lightweight kernels for sparse gradient injection and transposition, scheduling different CTAs on CUDA Cores to handle or Tensor Cores to handle . We directly use these kernels to compute the remaining operations during the forward pass while storing the intermediate representations and in the same hybrid representations, and then recover the input and weight gradients , , , and entirely through efficient sparse and hybrid kernels, without any dense-to-dense matrix multiplication during backpropagation.
This design allows us to aggressively compress the sparse activations without becoming brittle to the highly non-uniform row-wise sparsity patterns observed during training. In contrast to inference, the training pipeline is organized around the full training step, where costs are dominated by backpropagation. In this setting, the hybrid representation purposefully foregoes the benefits of fused execution to effectively minimize memory traffic and recomputation, maximizing throughput across the entire backward pass.
Evaluating the Performance and Efficiency of Sparse LLMs
For our quantitative evaluation, we train LLMs at billion-parameter scales across different sparsity levels and model sizes and evaluate their performance and efficiency on powerful H100 GPUs.


We start by evaluating the effect of L1 regularization on the performance and activations of a 1.5B parameter model after training, evaluating on seven popular downstream tasks


We contrast our performance results by analyzing the efficiency of our sparse 1.5B LLMs powered by our optimized kernels. First, we examine the average throughput and total energy savings recorded during batched inference with our fused kernels. Across all sparsity levels, we observe significant speedups ranging up to 30%, which are compounded by nearly 3% less GPU power draw above , resulting in even higher energy savings. Second, we examine the average throughput and peak memory reductions achieved during training with our specialized hybrid kernels. In line with batched inference, we record significant training speedups ranging up to 24% with sparser models, together with peak GPU memory reductions exceeding 24% even for the lowest considered sparsity level. Taken together, these results validate that our optimized kernels provide meaningful efficiency improvements across the full LLM lifecycle, turning sparsity into a potentially viable axis for future LLM design.
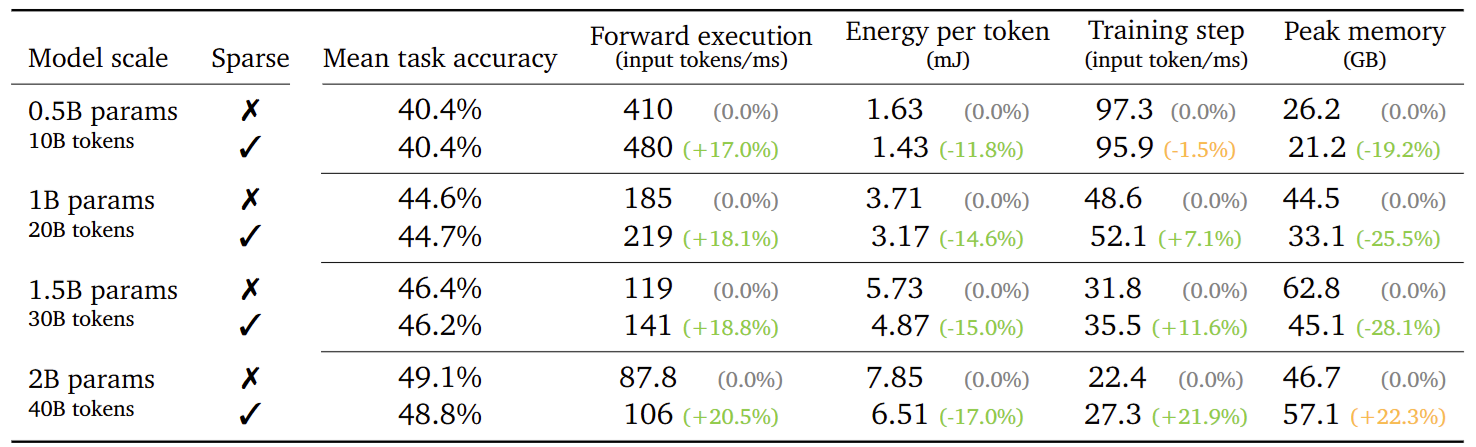
Additionally, we analyze how the performance and efficiency of sparse LLMs are affected by model size and training budget, while fixing the regularization level to . In line with our previous results, we find no significant performance degradation in downstream accuracy beyond random deviations across all examined model sizes and training budgets. Furthermore, we find that LLMs become increasingly effective at supporting sparsity at larger scales, resulting in a 38% lower non-zero activations when going from the 0.5B to the 2B model. As a result, this makes all the aforementioned throughput and memory benefits of our kernels grow, with our 2B sparse model processing tokens 20.5% faster during inference and fitting double the micro-batch size to train 21.9% faster.
Conclusion
In this collaboration between Sakana AI and NVIDIA, we leverage unstructured sparsity to lessen the computational burdens of modern LLMs. We introduce the TwELL data format and a set of optimized CUDA kernels tailored to fit the execution patterns of LLMs on modern GPUs. By training and evaluating sparse models at billion-parameter scales, we show that our kernels can translate the sparsity levels induced by mild L1 regularization into higher throughput, lower memory requirements, and reduced energy expenditure. Moreover, these benefits appear to grow with model scale, highlighting its potential relevance for scaling future model development. We refer to our technical report for additional details and results, demonstrating how these gains become even more pronounced on less capable NVIDIA hardware and analyzing activation patterns across different layers and input tokens to understand what triggers sparsity in different LLMs. We will release and open-source all of our kernels to facilitate future research and development into hardware-aware algorithms and efficient LLMs.