String Seed of Thought: Prompting LLMs for Distribution-Faithful and Diverse Generation
Can LLMs Flip Coins in Their Heads?
In recent years, LLMs have become increasingly strong on tasks with a single, well-defined answer
First off, what does it even mean to have an LLM flip a coin in its head? Concretely, suppose we prompt an LLM with "Flip a fair coin" and ask it to output either "Heads" or "Tails".
Let's say it outputs "Heads". With just this single trial, we can't tell if the LLM is actually flipping a coin in its head. The LLM might just be cheating by skipping the mental "coin flip" entirely and simply outputting "Heads" because it seems like a plausible answer. To verify this quantitatively, let's have it perform this coin flip many times, say 1,000 times. By counting how many times out of 1,000 the LLM outputs Heads versus Tails, we can assess whether its outputs are statistically consistent with a fair coin.
When we actually run this experiment and look at the results, we find that the counts for Heads and Tails stray far from the expected 500 each. In short, many frontier LLMs we tested show systematic bias when prompted directly like this. We conducted further experiments on various scenarios, such as choices with more than two options or skewed probabilities, and confirmed the following general finding:
Beyond the coin flip, consider an LLM playing poker. In poker, there is a tactic known as bluffing: a strategy where a player bets or raises with a hand that is likely not the best to make opponents fold better hands. For instance, in a simplified poker variant called Kuhn Poker
Is there a way to solve this problem entirely within the LLM's head, without relying on external tools? Even more ambitiously, can we achieve this just by tweaking the prompt a little? Our answer is Yes. To achieve this, we propose a prompting method called String Seed of Thought (SSoT).
String Seed of Thought (SSoT)
SSoT is a simple technique: we just add the following two instructions to the prompt given to the LLM. (1) Have the LLM generate a random string in its head first (without using a pseudo-random number generator, or PRNG), and (2) have it perform operations on that string in its head to simulate a coin flip. That's it!
By simply providing this prompt, the LLM can often adopt strategies like the following even without specific step-by-step instructions. For instance, we frequently observe the LLM coming up with a random string in its head, calculating the sum of the ASCII codes of that string, and taking the result modulo 2. It then outputs Heads if the result is 0, and Tails if the result is 1.
Through our experiments, we confirmed that SSoT substantially reduces output bias across a wide range of LLMs, and achieves performance approaching that of a PRNG, especially with reasoning models. In short, by making a minor tweak to the prompt using SSoT, LLMs gain the ability to flip a coin in their heads.
SSoT isn't just for reducing bias; it has another useful application: increasing output diversity in open-ended tasks like creative writing. Just like with the coin flip, simply instructing the model to "generate a random string in your head and manipulate it to produce a diverse output" enables you to get much more varied responses from the exact same prompt.
So far, we've outlined the kinds of problems SSoT solves. Let's refer to the first type of task, like the coin flip, as Probabilistic Instruction Following (PIF), and the second type, increasing output diversity in open-ended tasks, as Diversity-Aware Generation (DAG). In the following sections, we'll dive deeper into SSoT's actual performance in PIF and DAG, as well as the underlying mechanisms that make SSoT work.
PIF
DAG
Below are simplified variants of the SSoT system prompt, reproduced from Appendix D.4 of the paper. The full experimental prompts used in the main PIF, RPS, and DAG experiments are longer and are listed in Appendix A of the full paper.
Simplified SSoT Prompt for PIF
Generate a complex random string between <random_string> and </random_string>, and manipulate this string to guide any stochastic decisions within <thinking> and </thinking> tags.
Then, provide your final answer, enclosed within <answer> and </answer> tags.
Simplified SSoT Prompt for DAG
You must produce exactly one unique and diverse answer. To do this, first generate a complex random string between <random_string> and </random_string>, and manipulate this string to guide any stochastic decisions within <thinking> and </thinking> tags.
Then, provide your final answer, enclosed within <answer> and </answer> tags.
Experimental Results
SSoT Reduces Output Bias Across Various LLMs
We evaluated the performance of SSoT across various LLMs on n-choice problems, testing both uniform distributions (like a fair coin flip) and biased distributions. For each setting, we conducted 100 trials to form a single set, repeating this 10 times to estimate the error bars. We used Jensen–Shannon divergence (JS divergence) as our evaluation metric; this metric measures the similarity between two probability distributions, meaning a value closer to 0 indicates higher fidelity to the target distribution.
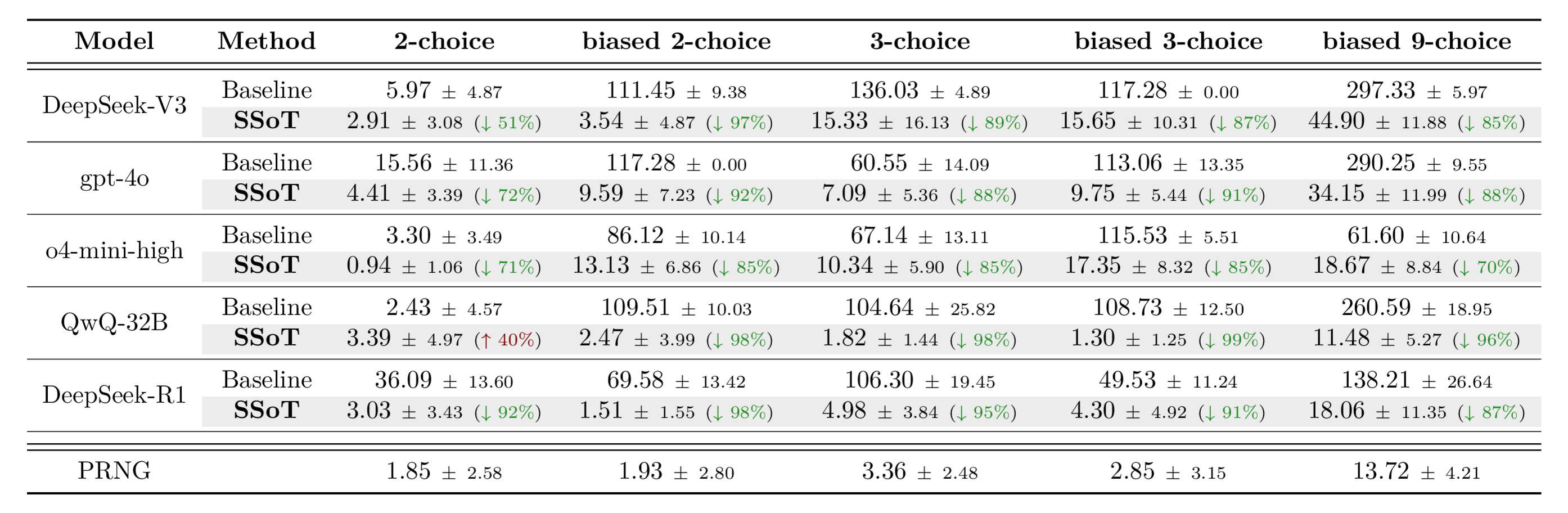
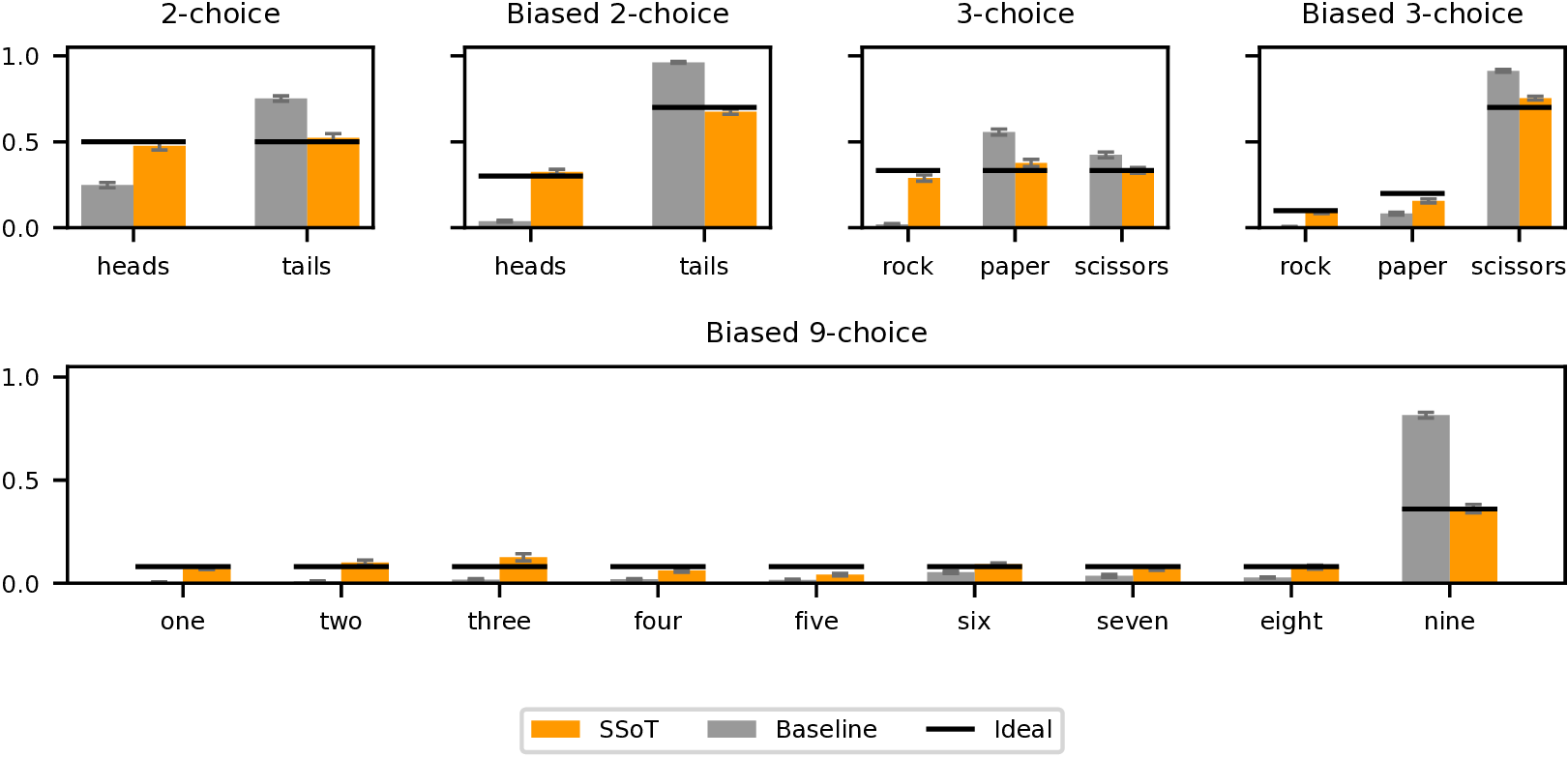
As shown, SSoT substantially reduces output distribution bias across a wide range of LLMs and task types. Furthermore, for DeepSeek-R1, SSoT approaches the sampling quality of a PRNG. One notable exception is QwQ-32B on the unbiased 2-choice task, where the baseline's JS divergence of 2.43 is already near the PRNG reference and SSoT lands slightly higher at 3.39; see the paper's failure analysis for details.
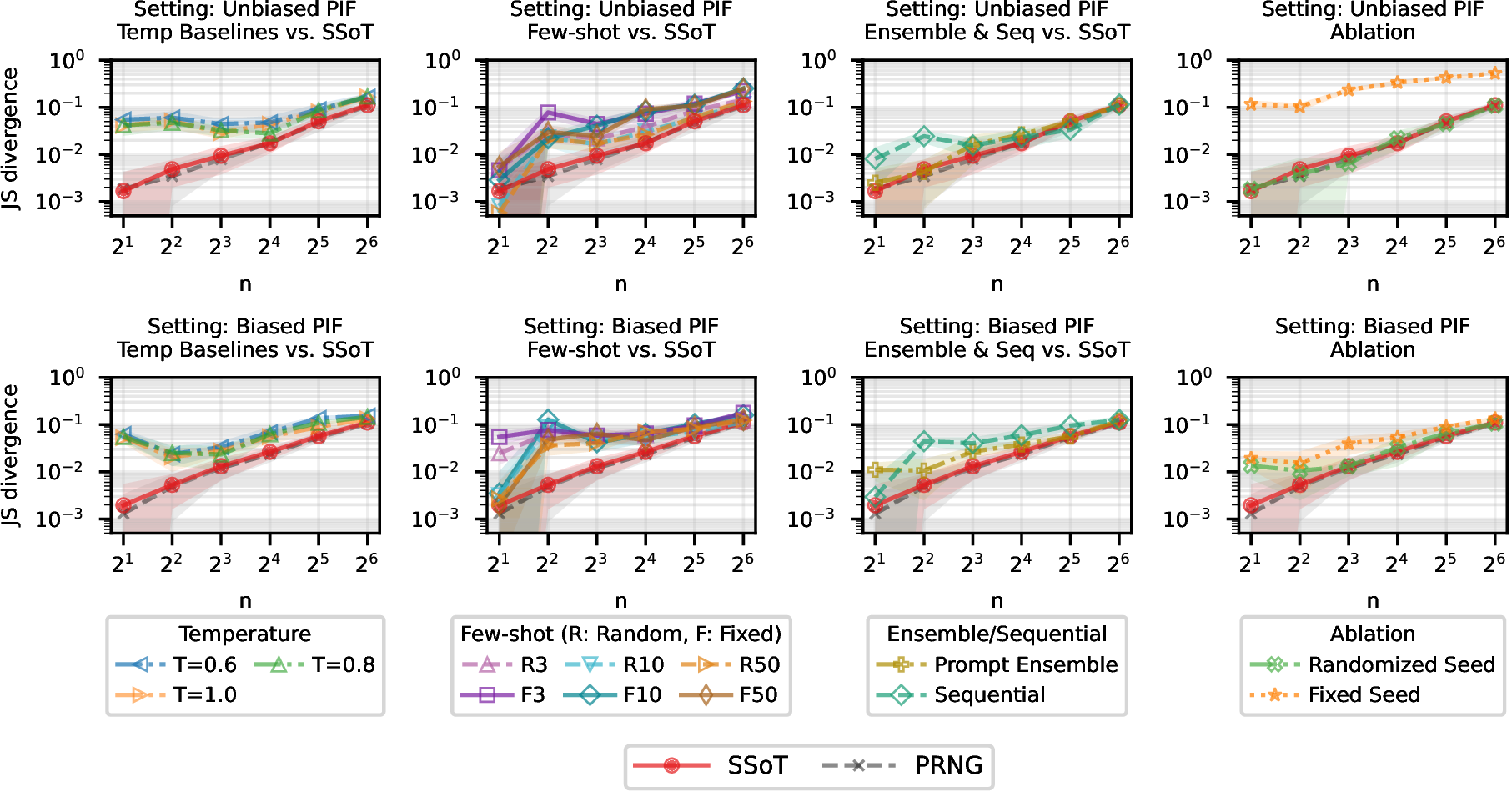
SSoT Outperforms Other Prompting Methods in Reducing Bias
Next, focusing on DeepSeek-R1, we demonstrate that SSoT reduces bias much more effectively than other baseline prompting methods (such as high-temperature sampling, few-shot prompting, prompt ensembling, or sequential sampling) across various action space sizes. The figure below plots the JS Divergence (lower is better), where the red line represents SSoT and the black dashed line indicates the ideal PRNG distribution. Across every setting, SSoT consistently surpasses all other bias-reduction prompting techniques.
SSoT Reduces Bias in Probabilistic Game Strategies
The capabilities of PIF translate directly to game theory applications. Building on our earlier discussion about the strength of probabilistic choices in games, the mixed-strategy Nash equilibrium for Rock-Paper-Scissors is playing each move with an equal 1/3 probability. SSoT substantially reduces the LLM's sampling bias, making its play much harder to exploit for strong pattern-hunting opponents
In this experiment, we compare three types of prompts. Both SSoT and the Baseline explicitly instruct the model to "select moves from Nash equilibrium strategies," but they differ in how probabilistic sampling is executed:
- SSoT: This prompt instructs the LLM to probabilistically select a move from the Nash equilibrium mixed strategy. Crucially, it requires the model to generate a random string as a seed, and then guide its probabilistic move selection based on that seed.
- Baseline: This prompt simply instructs the model to vary its move selection based on the Nash equilibrium to avoid being exploited. It provides no concrete mechanism for randomization, leaving the LLM to generate randomness purely in its head.
- Simple: A naive prompt that simply tells the model to pick moves that maximize its chances of winning and vary its selection because opponents will look for patterns. It makes no mention of Nash equilibria.
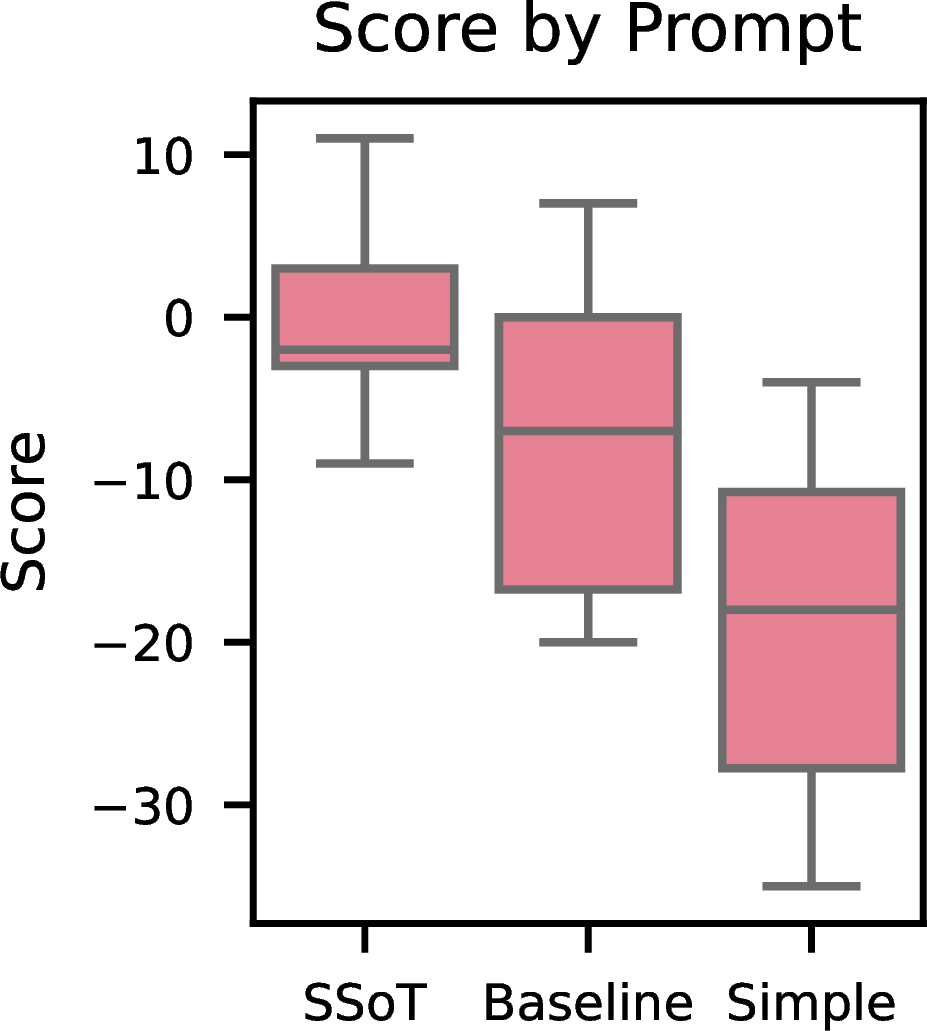
For each prompt, we pitted the LLM against 10 different "black belt" bots for 100 games each, scoring each match as wins minus losses (range: -100 to +100). The bots have full access to the move history of both players while the LLM does not, so any predictable patterns get exploited. The box plot below shows the distribution of final scores. SSoT maintains an average score near zero, behaving more consistently with mixed-strategy play and largely holding its own against the exploiters. The Baseline prompt aims for the Nash equilibrium but still exhibits exploitable sampling biases, and the Simple prompt lacks sufficient strategic diversity and is consistently defeated.
Diversity-Aware Generation
To demonstrate that SSoT enhances diversity in open-ended tasks, we evaluated its performance on NoveltyBench
Our evaluation uses the following two metrics defined by NoveltyBench. For each prompt, we generated responses from the LLM and calculated the following:
- Distinct (Diversity): This metric quantifies diversity by using a classifier to partition the 8 generated responses into functionally equivalent classes. It is calculated as the count of unique classes. The score ranges from 1 to 8; higher values indicate greater diversity among the outputs.
- Utility (Diversity × Quality): This metric combines diversity and quality by summing the reward scores of only the novel generations (i.e., those belonging to a newly discovered equivalence class). These scores are discounted by a user patience factor based on their appearance order. A higher value indicates that the model generated responses that are both diverse and high-quality.
For both metrics, higher is better. The tables below present both scores in each cell, formatted as Distinct (Utility).

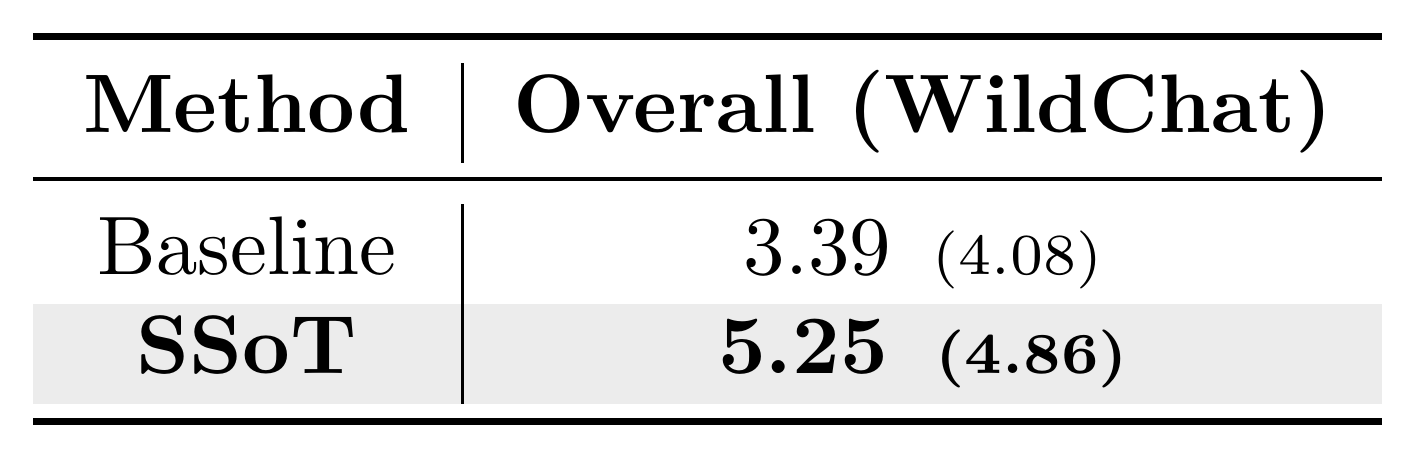
As shown, SSoT achieves the highest overall Distinct score on both datasets, and matches or exceeds the strongest baselines on most curated categories. In practice, this means users see far fewer repeated or near-duplicate answers across generations: each response is more likely to offer a genuinely different angle, phrasing, or idea. And crucially, this added diversity comes with little quality trade-off. The Utility score, which only credits responses that are both novel and high-reward, also rises clearly over the baseline, though on the curated set a few categories (e.g., Product Recs, Opinions) are still led by Paraphrase or higher-temperature sampling on Utility.
The Mechanism of SSoT
Now that we have seen SSoT in action, let's explore what is happening under the hood. While the SSoT prompt itself doesn't specify how to manipulate the random string, our analysis of reasoning traces reveals that LLMs autonomously adopt effective strategies based on the task. The strategies differ between PIF and DAG, so we examine each in turn.
Mechanism for PIF: Sum-Mod and Rolling Hash
For PIF tasks, LLMs choose a string-manipulation strategy based on the target probability distribution and the number of choices. We frequently observed two representative strategies:
- Sum-Mod: Determines the output by summing the ASCII values of each character in the random string and taking the result modulo the number of choices. For example, in a fair coin flip, if
sum(ASCII) mod 2is 0, it outputs Heads; if 1, Tails. It is simple and suited for equal-probability selections. - Rolling Hash: Processes the string character by character to sequentially update a hash value. For example, it computes
hash = (hash × 31 + ASCII value) mod Mand determines the output from the final hash. Because the hash value takes a large range of integers (0 to ), it can naturally express arbitrary probability ratios via threshold splits, making it well-suited for biased distributions (e.g., 30/70).
You can see these operations, Fair Coin Flip (Sum-Mod) and Biased Coin Flip (Rolling Hash), in action in the animation below.
SSoT for Probabilistic Instruction Following (PIF)
Watch SSoT for PIF in action. The LLM internally generates a random string and manipulates it (via Sum-Mod or Rolling Hash) to sample from the target distribution, with no external tools needed.
<random_string> and </random_string>, and manipulate this string to guide any stochastic decisions within <thinking> and </thinking> tags.Then, provide your final answer, enclosed within
<answer> and </answer> tags.Mechanism for DAG: Template-Based Generation
Next, what about DAG? Our analysis shows that LLMs autonomously adapt their generation strategy here as well. One representative approach is template-based generation. For example, when asked to write a fable, the LLM decomposes story components (setting, traits, conflict, moral, etc.) into categories, and selects candidates for each using a Sum-Mod operation on different segments of the random string. Different strings result in different combinations of elements, generating diverse stories from the same prompt. You can see this process in action in the animation below.
SSoT for Diversity-Aware Generation (DAG)
In diversity-aware generation, the LLM uses the random string to make deterministic creative decisions. A different string leads to different decisions and a different story.
<random_string> and </random_string>, and manipulate this string to guide any stochastic decisions within <thinking> and </thinking> tags.Then, provide your final answer, enclosed within
<answer> and </answer> tags.Conclusion
We proposed SSoT, a prompting method that reduces bias in probabilistic sampling and improves output diversity entirely within the LLM, without external tools. SSoT requires only a minor modification to the prompt: for PIF, it was effective across the five frontier LLMs we tested, and for DAG, we observed clear diversity gains for DeepSeek-R1 on NoveltyBench. In practice, SSoT can be adopted by adding a few lines to the system prompt of your API calls.
On the other hand, SSoT has a few limitations. Because it relies on the model's ability to autonomously devise and execute strategies like modulo arithmetic or hashing, its effectiveness decreases in smaller models with limited reasoning capabilities. Additionally, SSoT is designed for tasks with multiple valid answers or probabilistic requirements: on tasks that have a single correct answer (such as math problems or factual retrieval), applying SSoT is not effective and could potentially distract the model.
In the paper's CoT-scaling analysis, longer reasoning traces were associated with more faithful sampling from the target distribution, suggesting that extra inference tokens can be traded for higher PIF fidelity in long-reasoning models. Other topics covered include a theoretical analysis of why SSoT works, detailed analyses of model-size dependence and per-model failure modes such as QwQ-32B's bias on 2-choice tasks, and concrete DAG output examples. If you are interested, please check out the full paper.